Pythonで実装するSVM。AI初心者でもわかる機械学習アルゴリズムの基礎と実装
SVM(Support Vector Machine)モデルとは、分類や予測を行う機械学習の手法の1つであり、複雑なデータを分類して分析することができます。本ブログでは、SVMモデルの基礎的な概念から、実際のデータ分析に応用する方法まで、初心者にも理解しやすいように解説しています。初心者の方や機械学習に興味がある方は、ぜひ参考にしてみてください
目次
SVMとは?
SVM(Support Vector Machine)は、データ点を最適に分離する超平面を特徴空間内に見つけることに焦点を当てた機械学習アルゴリズムです。SVMでは、線形SVMと非線形SVMの2つの主要なバリエーションがあります。線形SVMは、データが直線的に分離可能な場合に使用されます。非線形SVMは、より複雑な分離問題を扱うことができます。
SVMの基本的な考え方は、2つのクラスを分離するための最適な境界を見つけることです。データ点が境界線から最も近い位置にある点をサポートベクターと呼びます。このサポートベクターと境界線の距離(マージン)が最大になるような境界線を見つけ、最適な分離を実現します。
画像引用:サポートベクターマシン (SVM)

プログラム解説〜データ前処理〜
今回はこちらのKaggleのKickstarter Projectsのデータを例に実践していきます。KaggleのKickstarter Projectsは、クラウドファンディングサイト「Kickstarter」で行われたプロジェクトのデータセットです。データセットには、プロジェクト名、カテゴリー、開始日、終了日、目標金額、資金調達額、支援者の数、プロジェクト状況など、さまざまな情報が含まれています。
Kickstarter Projects
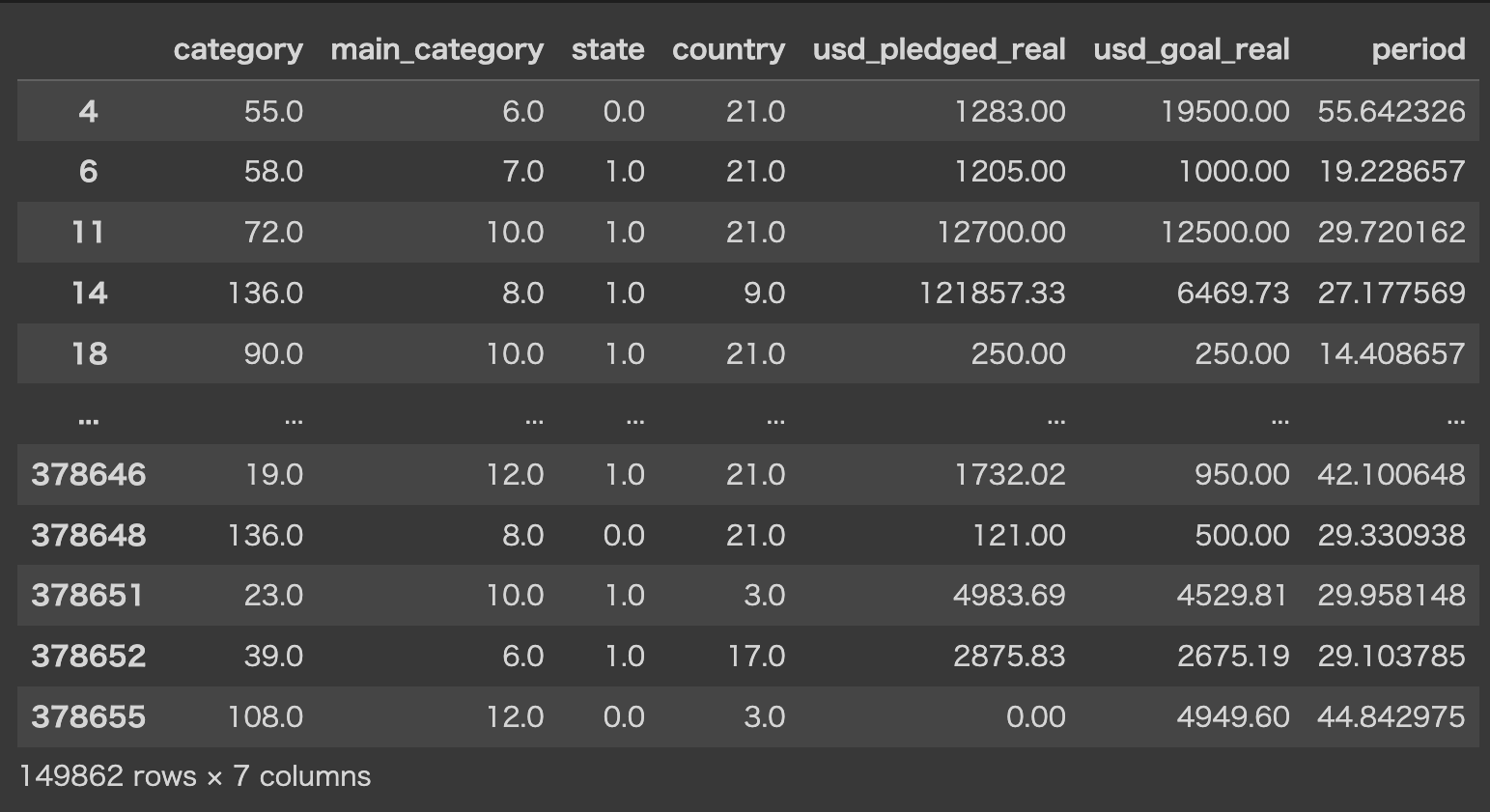
データ前処理を済ませたデータがこちらになります。
プログラム解説 〜データの標準化と分割処理〜
まず、下記のコードを実行し、説明変数の標準化とデータの分割処理を行います。

プログラム解説 〜モデルの学習〜
次に下記コードを実行しモデルの初期化と学習を行います。これでSVMモデルの実装は完成です。
プログラム解説 〜予測値の出力&モデル性能評価〜
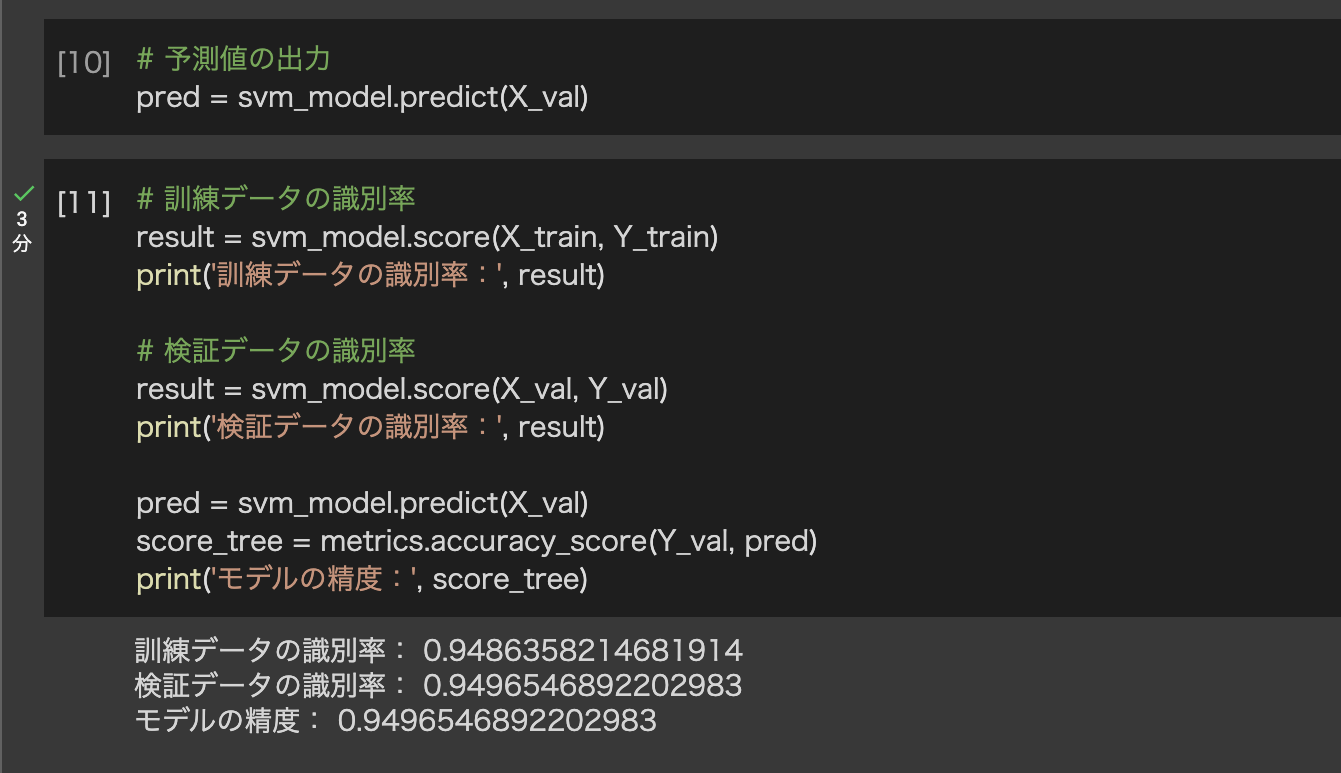
次は、実装した決定木モデルの精度評価をしていきます。今回は訓練データと検証データの識別率とモデル自体の性能評価を行なっていきます。
この結果から、過学習を起こさず性能の高いモデルが実装できていることが確認できます。
プログラムの全容
今回、実装したプログラムは下記リンクから詳細を確認することができます。是非ご活用ください。
Google Colaboratory



