【AIエンジニア必見】データ理解の負担を減らすpandas profiling

AIモデルやBI開発をする際には、探索的データ分析(EDA)の作業が必要です。この作業は、そのデータの概要を理解するために多大な時間と労力が必要です。このデータ理解の作業負担を大幅に削減できるのが「pandas profiling」です。「pandas profiling」はPythonのデータ分析ライブラリpandasの拡張ライブラリであり、データフレームの構造や統計情報を自動的に生成してくれるツールです。この記事では、「pandas profiling」の使い方を解説していきます。
目次
pandas profilingのインストール
まずは、「pandas profiling」をインストールしましょう。以下のコマンドをコマンドプロンプトやターミナルで実行してください。
pip install pandas-profiling
pandas profilingを使用したレポート作成
次に、実際に「pandas profiling」を使用してデータ分析をしてみましょう。今回はこちらのKaggleのKickstarter Projectsのデータを例に実践していきます。KaggleのKickstarter Projectsは、クラウドファンディングサイト「Kickstarter」で行われたプロジェクトのデータセットです。データセットには、プロジェクト名、カテゴリー、開始日、終了日、目標金額、資金調達額、支援者の数、プロジェクト状況など、さまざまな情報が含まれています。
Kickstarter Projects
まずは、以下のように「pandas」でデータを読み込みます。
import pandas as pd
df = pd.read_csv(‘ks-projects-201801.csv’)
次に、「pandas profiling」を使用してデータの概要を調べてみましょう。以下のようにコードを書きます。
from pandas_profiling import ProfileReport
profile = ProfileReport(df) profile.to_file(output_file=’report.html’)
このコードを実行すると、「report.html」というファイルが生成されます。このファイルをブラウザで開くと、データの概要が分かるレポートが表示されます。
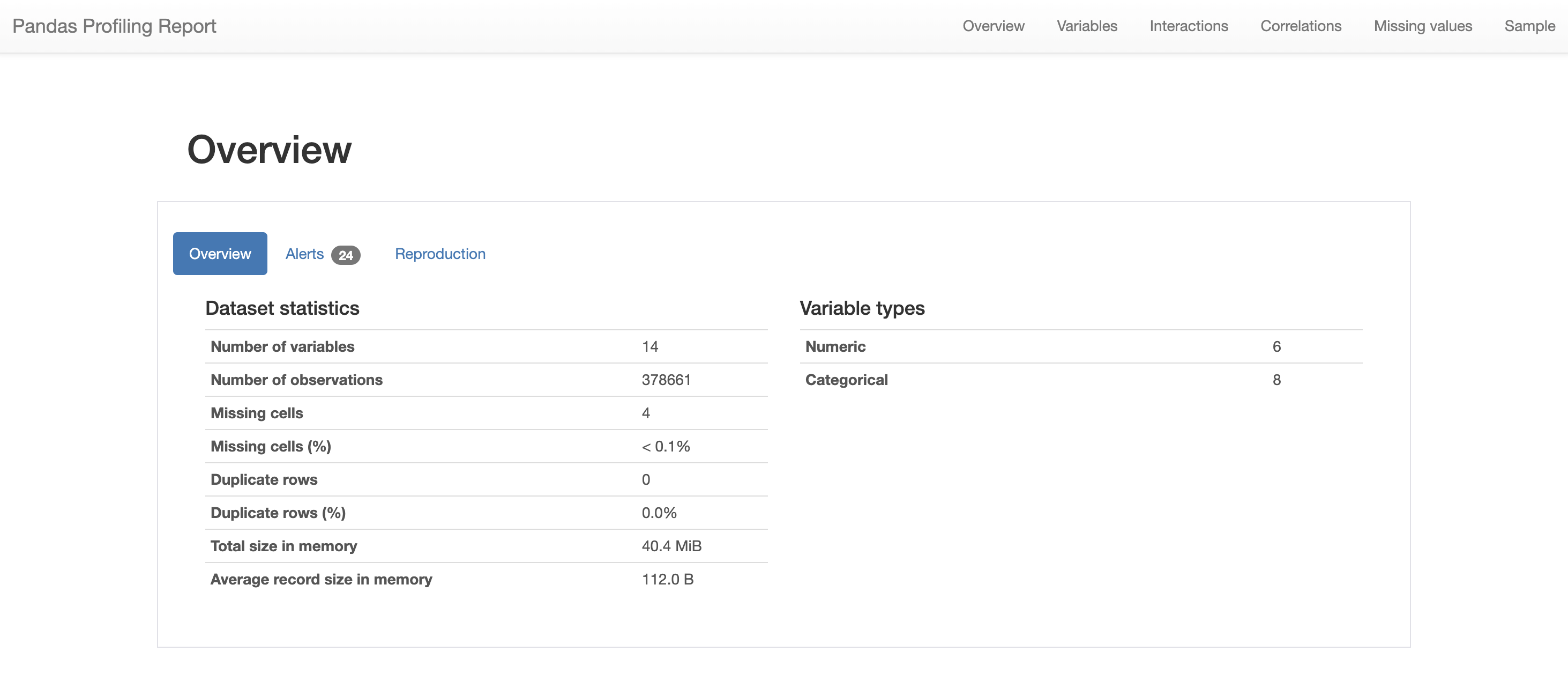
Pandas Profiling Reportの詳細 ~Overview~
こちらがそのレポートの内容です。「Overview」では、各変数の型やデータの容量、データサイズなど、そのデータの概要に関しての情報を知ることができます。
Pandas Profiling Reportの詳細 ~Variables~
「Overview」の下には「Variables」と呼ばれる変数それぞれの特性を評価できる項目があります。こちらの変数categoryを例に取ってみると、欠損値の可否や、ユニーク値の頻出順位などが視覚的に把握することができます。こちらは文字列データですが、数値データの場合は中央値や四分位範囲などが算出されており、データの概要を理解するのに必要な情報が揃っています。

Pandas Profiling Reportの詳細 ~Missing Values~
「Missing Values」では、各変数の欠損値以外のデータの個数が可視化されています。

おわりに
このように、「pandas profiling」を使用することで、手軽にデータの概要を把握することができます。
今回紹介したもの以外にもレポートには、以下のような情報が含まれています。
・相関分析
・外れ値の検出
・頻出値や極端な値の分布
個人的には、作成した HTML ファイルを共有することで、複数人が同じレポートを共有して閲覧できるのが非常に便利に感じています。皆様も是非活用してみてください。



