【databricks】PySparkとMLflowを活用した機械学習モデルの構築ガイド
近年、機械学習はビジネスの成長において欠かせない技術となっています。しかし、機械学習モデルの開発や管理には、機械学習だけでなくデータの管理やセキュリティ管理などの多くの課題があります。今回はDatabricksを活用し、PySparkとMLflowを使った効率的な機械学習モデル構築と管理の方法を詳しく解説します。
目次
はじめに
近年、機械学習はビジネスの成長において欠かせない技術となっています。しかし、機械学習モデルの開発や管理には、機械学習だけでなくデータの管理やセキュリティ管理などの多くの課題があります。今回はDatabricksを活用し、PySparkとMLflowを使った効率的な機械学習モデル構築と管理の方法を詳しく解説します。
Databricksとは

Databricksはデータ分析とAI運用を統合し、構築・デプロイ・共有・保守まで行える総合的な分析プラットフォームです。特に以下のような特性から多くの企業に求められています。
- 統合された分析環境:データの取り込みから分析・可視化・共有までシームレスに行える。
- スケーラブルで柔軟な環境:クラウドベースのため、大規模データに柔軟に対応可能。
- セキュリティとガバナンス:企業レベルの厳格なセキュリティ基準を満たす。
- チームコラボレーション:コードや分析結果を容易に共有でき、協業を促進。
databricks上にはこれらを実現するためのコンポーネントが様々ありますが、今回のブログではDatabricks上の主要コンポーネントである「PySpark」と「MLflow」について紹介したいと思います。
PySparkの基礎知識
PySparkは、Databricksで使用されるPythonのAPIであり、Apache Sparkの強力な処理能力をPython環境で手軽に活用できます。
PySparkの特徴とメリット
PySparkは深層学習などの計算コストが重い場合に特に有用です。ここではPySparkの2つの特徴について見ていきましょう。
一つ目の特徴は処理が高速かつ、大規模であるということです。これによりコストが重い計算を比較的容易に終わらせることが出来ます。PySparkではメモリ上でデータを保持して処理を行うためデータへのアクセス時間を短縮しています。また分散処理を採用しているため、並列に処理を行うことが出来、高速で実行することが出来ます。さらにCPUの最適化やメモリの管理を制御しながら処理を進めます。このような性質により高速かつ大規模な処理を実現しています。

二つ目の特徴は多様な処理方法を持つということです。Sparkは多様なAPIを提供しており、様々な言語で使用できます。また豊富なライブラリを提供しており、機械学習処理はもちろんグラフデータの処理なども出来ます。さらに環境依存せず、クラウド環境、コンテナ環境など様々な環境で使用することが出来ます。このようにSparkは多様な処理方法を持ち、他場面で活用できるのです。

ここまでPySparkの紹介をしました。以下では2つ目のコンポーネントであるMLflowについて紹介します。
MLflowとは
MLflowは機械学習の開発から運用までのライフサイクルを効率的に管理するプラットフォームです。機械学習開発を行うときの煩雑さや運用時の課題を解消します。MLflowを使用することで実験、モデルを記録し、外部環境で同実験を行うためのパッケージを作成し、共同でモデルを開発するためのプラットフォームの活用などが出来ます。以下ではMLflowの4つのコンポーネントについて詳細を確認していきます。
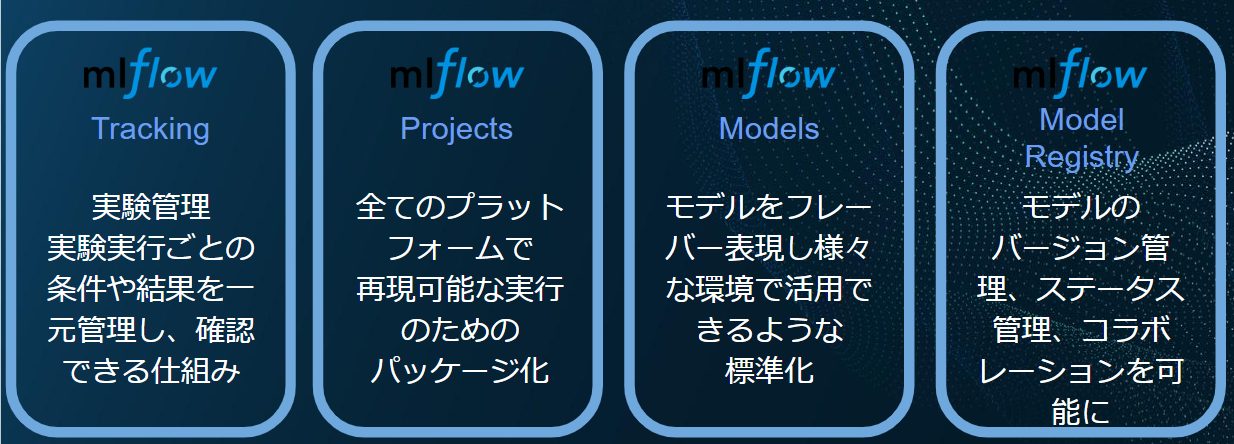
MLflowの4つのコンポーネント
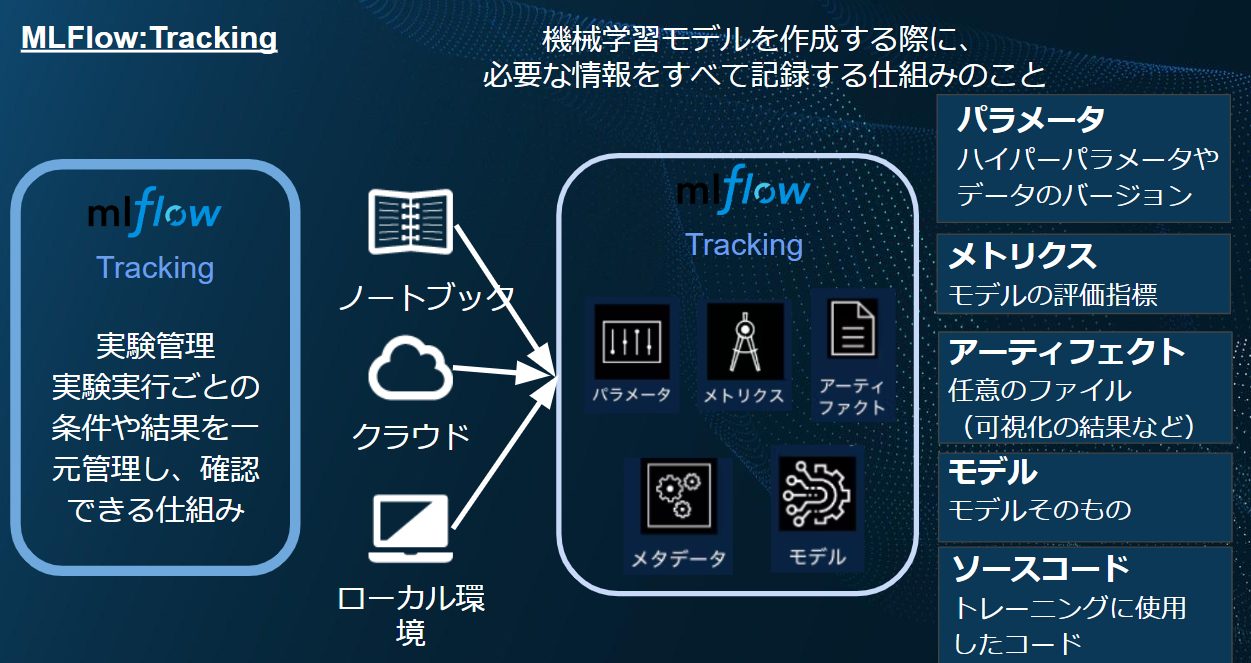
・Tracking(実験管理):
機械学習モデルを作成する際に、必要な情報をすべて記録。これによりいかなる時でもモデルのパラメータやメトリクス、ソースコードを参照することが出来ます。
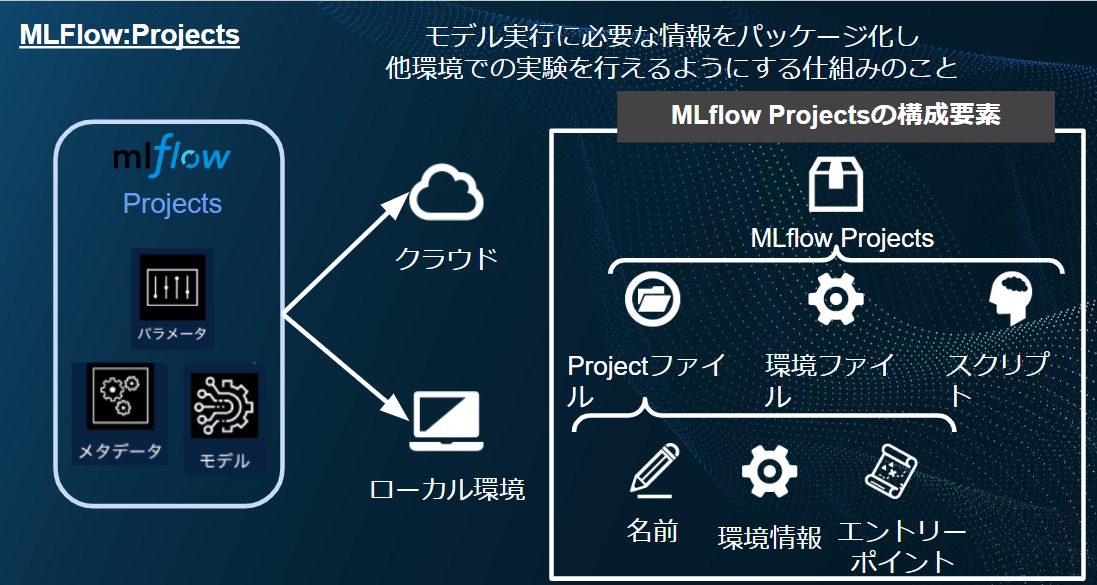
- Projects(再現性):
モデル実行に必要な情報をパッケージ化し、他環境での実験を行えるようにする仕組みです。databricks上で行われた実験をパッケージ化することでローカル環境や他クラウド環境などその他の環境でも同様の実験をすることが出来ます。
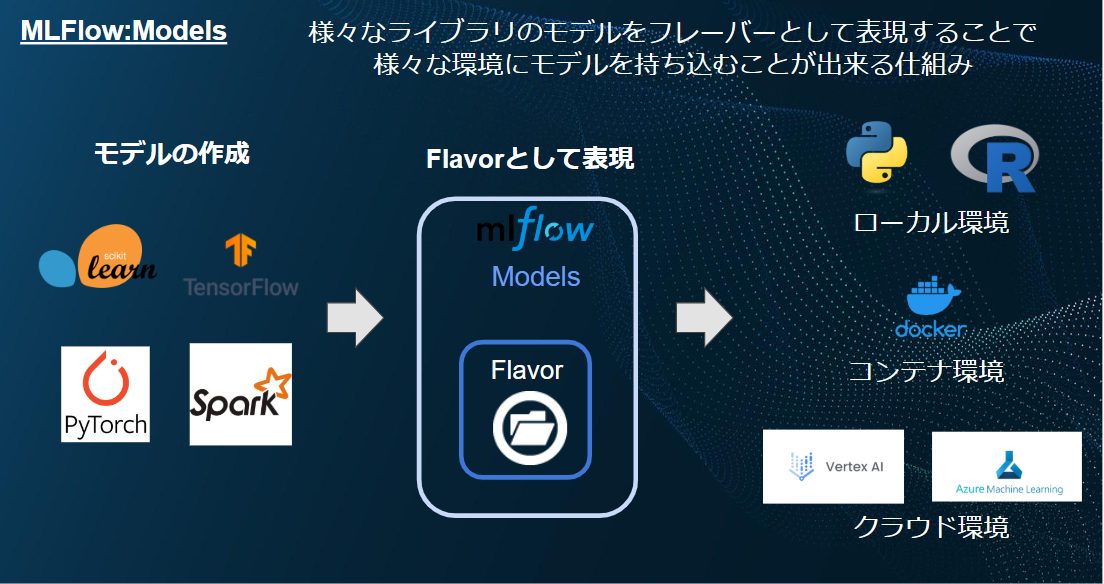
- Models(モデル管理):
様々なライブラリで作成したモデルを一度「フレイバー」形式として表現することでローカル環境やコンテナ環境など様々な環境にモデルそのものを持ち込むことが出来ます。
- Model Registry(モデルレジストリ):
機械学習モデルの一元管理やコラボレーションを可能にするような機能です。ここでgithubのように作成したモデルに対するレビューなどを行うことが出来ます。
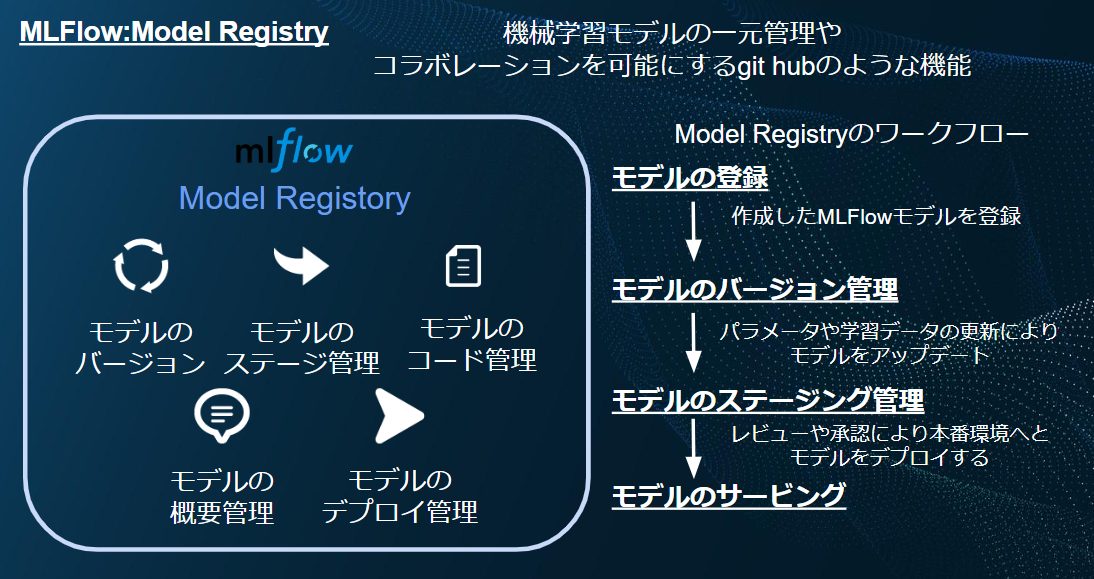
このようにして機械学習モデルを作成することで一元管理を可能にすることが出来ます。
MLflowが優れている理由と具体的なユースケース
MLflowの強みは、機械学習の実験や運用を簡素化・標準化し、効率を劇的に向上させることです。具体的なユースケースとしては、以下のような例があります。
- 金融業界:リスク評価モデルの開発とリアルタイムモニタリングに活用。
- 製造業界:製品品質予測モデルを継続的に改善・管理するために導入。
- 小売業界:売上予測モデルを頻繁に更新・検証し、迅速な意思決定をサポート。
このように様々な業界で機械学習が使用されており、その効率化をMLflowにより行うことが出来ます。
終わりに
Databricks、PySpark、そしてMLflowを効果的に活用することで、機械学習モデルの開発と運用の課題を解決できます。ぜひ本記事を参考にし、効率的で効果的な機械学習運用を実現してください。


