GraphRAG - 知識グラフRAG
従来のRAGシステムは、テキストを分割してベクトル化するだけで、文脈や関係性が失われてしまう課題がありました。GraphRAGは、この問題を解決する次世代のRAG技術です。本記事では、GraphRAGの仕組みから実装方法まで、実例を交えて詳しく解説します。
目次
1 デモコード
2 知識グラフとは
エンティティ(ノード)と関係性(エッジ)で情報を構造化する手法
例:知識グラフの構造
テキスト: "Joseph Wells founded ACFE in 1988"
↓ グラフ化
[Joseph Wells] --FOUNDED(1988)--> [ACFE]
(person) (organization)
知識グラフの利点
- 関係性を明示的に表現 – 「誰が」「何を」「いつ」が明確
- 構造的な情報取得 – エンティティを起点に周辺情報を辿れる
- 推論が可能 – 間接的な関係も発見できる
3 GraphRAGとは
テキスト → 知識グラフ構築 → グラフ+ベクトルで検索
従来のRAG(ベクトル検索のみ)
テキスト → チャンク分割 → ベクトル化 → 類似度検索
問題点:
- 関係性が失われる(文章が分断される)
- 文脈を理解できない
- 複雑な質問に対応できない
GraphRAG(グラフ+ベクトル)
【GraphRAG】
テキスト
↓
エンティティ抽出
- 人物、組織、イベントを特定
↓
グラフ構築(今回はLLMを使用)
- 関係性を接続
- 例: Joseph Wells --創設--> ACFE
↓
コミュニティ検出
- 関連エンティティをグループ化
- 階層化: Level 0(大) → Level 1(中) → Level 2(小)
↓
要約レポート生成
- 各コミュニティをAIが要約
↓
ベクトル化
├─ コミュニティレポート → グローバル検索
└─ テキストチャンク → ローカル検索
↓
構造的検索
解決したこと:
- ✅ 関係性を保持(グラフで明示)
- ✅ 構造的に理解(エンティティ間の繋がり)
- ✅ 複雑な質問にも対応(複数の視点から統合)
まとめ
従来RAG: テキストを切ってそのまま埋め込み
GraphRAG: テキストを理解→構造化→埋め込み → 理解してから埋め込むので、より賢い検索が可能
4 セットアップ
デモコード:https://github.com/adhazel/graphrag_demo/tree/main?tab=readme-ov-file
# 環境構築 python3.12 -m venv graphrag-env
source graphrag-env/bin/activate
pip install -r requirements.txt
# 初期化
python -m graphrag.index --init --root ./UseCaseA5 Use Case A Research Assistant.ipynb
仮想環境作成後にUse Case A Research Assistant.ipynbをダウンロードし、実行していく
フォルダまで作成してくれるので、簡単に実装できる
具体例:フォルダ作成
useCaseDir = "./UseCaseA"
folders_to_recreate = ["cache","input", "output"]
delete_all = True
import shutil
import os
if delete_all == True:
if os.path.exists(useCaseDir):
shutil.rmtree(useCaseDir)
os.mkdir(useCaseDir)
for folder in folders_to_recreate:
if os.path.exists(f"{useCaseDir}/{folder}"):
shutil.rmtree(f"{useCaseDir}/{folder}")
os.mkdir(f"{useCaseDir}/{folder}")6 設定
GRAPHRAG_API_KEY=sk-proj-xxxxxxxxxmodels:
default_chat_model:
type: openai_chat
model: gpt-4o-mini
api_key: ${GRAPHRAG_API_KEY}
concurrent_requests: 25
default_embedding_model:
type: openai_embedding model:
text-embedding-3-small
api_key: ${GRAPHRAG_API_KEY}
chunks:
size: 1200
overlap: 100
extract_graph:
entity_types: [organization, person, geo, event]
community_reports:
max_length: 2000
7 プロジェクト構造
UseCaseA/
├── .env # APIキー設定
├── settings.yaml # GraphRAG設定
├── input/ # ソースドキュメント(9記事)
├── output/ # 生成された知識グラフ
│ ├── entities.parquet # エンティティ(ノード)
│ ├── relationships.parquet # 関係性(エッジ)← グラフ本体
│ ├── communities.parquet # コミュニティ構造
│ ├── community_reports.parquet # AIが生成した要約
│ └── lancedb/ # ベクトル埋め込み
├── cache/ # APIレスポンスキャッシュ
├── logs/ # 実行ログ
└── prompts/ # LLMプロンプトテンプレート(13個)
8 インデックス作成(8ワークフロー)
# テキストから知識グラフを構築
index_result = await api.build_index(config=graphrag_config)処理フロー(全てgraphrag (v2.2.1) – Microsoft製のライブラリで実行)
GraphRAG Pipeline
STEP 1: create_base_text_units
IN: 9 Wikipedia files
DO: 1200字チャンク化(overlap=100, トークン境界調整)
OUT: 28 text chunks
STEP 2: create_final_documents
DO: メタ整理・ID付与・索引
OUT: documents.parquet
STEP 3: extract_graph ★最重要★
DO: 28チャンク×LLM並列抽出(gpt-4o-mini)
- エンティティ(TYPE: org/person/geo/event)
- 関係+強度スコア
OUT: 粗いKG(370 entities, 315 relationships)+キャッシュ
STEP 4: finalize_graph
DO: 重複統合、説明結合、関係正規化、一貫性チェック
OUT: entities.parquet / relationships.parquet
STEP 5: create_communities
DO: Leidenでコミュニティ検出(多層: L0=詳細, L1=抽象)
OUT: 25 communities(サイズ2~27)
STEP 6: create_final_text_units
DO: 各チャンクに entity_ids / relationship_ids を付与
OUT: text_units.parquet (28行)
STEP 7: create_community_reports ★重要★
DO: 25コミュニティ×LLM要約(タイトル/サマリ/評価/発見)
OUT: community_reports.parquet (25行)
STEP 8: generate_text_embeddings
DO: 3種を埋め込み(1536次元, text-embedding-3-small) → LanceDB
1) エンティティ説明 2) コミュニティ全文 3) テキストチャンク
OUT: *.lance(3インデックス)
完成:
- テキスト層:28チャンク+埋め込み
- エンティティ層:370/315(重み付き)
- コミュニティ層:25(L0=11, L1=14)+レポート
- 検索層:LanceDBベクトルストア(3種類)
生成されるグラフデータ
entities.parquet(ノード)
id | name | type | description
---|---------------|--------------|------------------
0 | ACFE | organization | 詐欺調査の専門組織
1 | Joseph Wells | person | ACFEの創設者
2 | Financial audit| event | 財務記録の検査
relationships.parquet(エッジ)
source | target | type | weight
-------------|-----------------|---------|-------
Joseph Wells | ACFE | FOUNDED | 0.9
ACFE | Fraud detection | RELATED | 0.8
communities.parquet(コミュニティ)
Level 0: 大きなコミュニティ(2-3個)
└─ Level 1: 中規模(5-10個)
└─ Level 2: 小規模(15-20個)
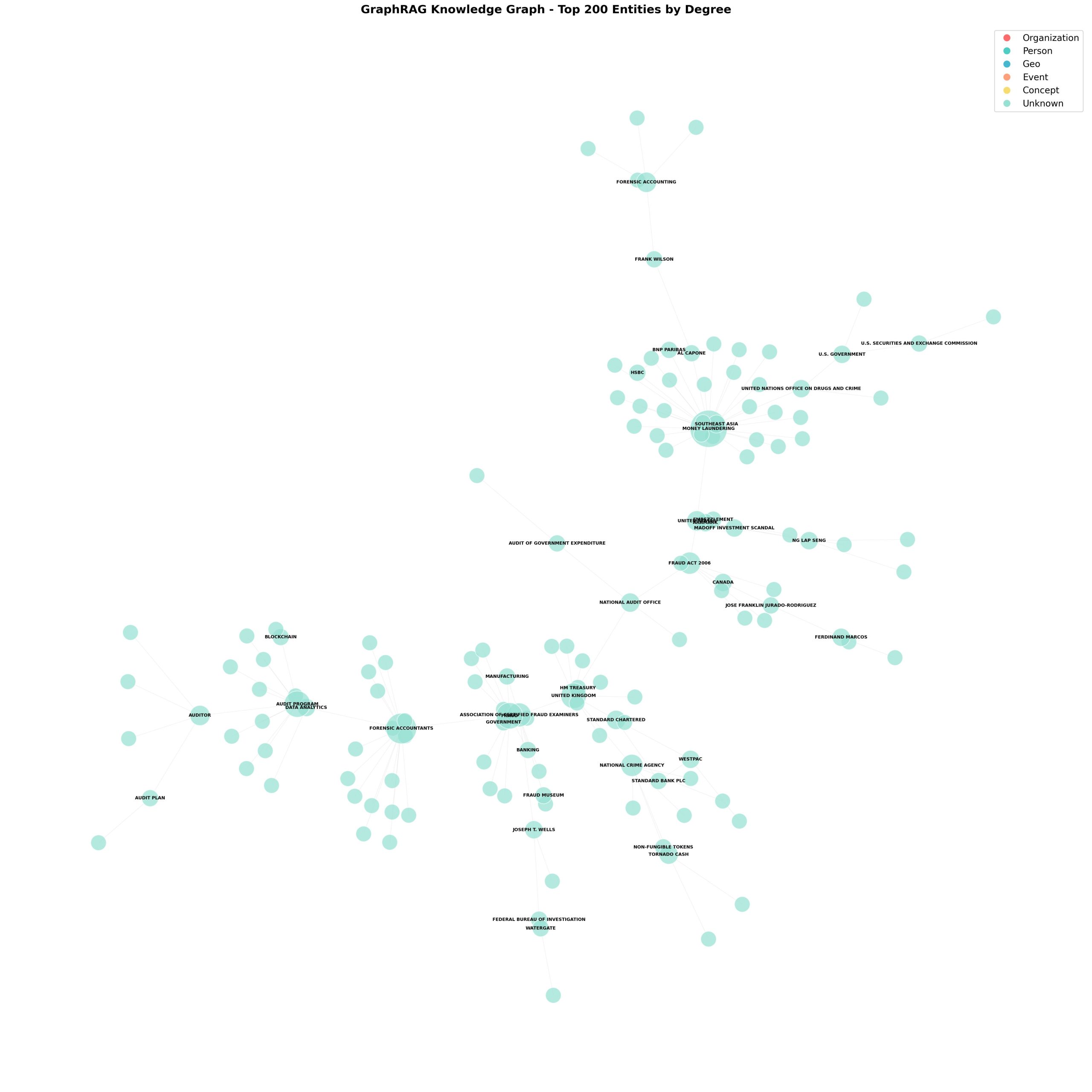
可視化
可視化しているのは:
- 元テキストデータ: 財務監査・不正検知に関する9つのWikipedia記事
- 処理後: GraphRAGが記事から自動抽出した370個のエンティティと315本の関係性
9 検索
# 生成された知識グラフをメモリにロード
entities = pd.read_parquet("output/entities.parquet")
communities = pd.read_parquet("output/communities.parquet")
community_reports = pd.read_parquet("output/community_reports.parquet")
知識グラフの使い方
知識グラフ(KG)
├─ エンティティ・関係性 → Local Searchが直接使用
└─ コミュニティレポート → Global Searchが使用
(KGをクラスタ化して要約したもの)
ポイント:
- Local = グラフ構造そのものを探索
- Global = グラフから作った要約を探索
1. Global Search(グローバル検索)
用途: データセット全体の包括的な質問
# Question 1: What are things I should think about when I am conducting an accounts payable audit?
response, context = await api.global_search(
config=graphrag_config,
entities=entities,
communities=communities,
community_reports=community_reports,
community_level=2,
dynamic_community_selection=False,
response_type="Multiple Paragraphs",
query="What are things I should think about when I am conducting an accounts payable audit?",
#買掛金監査を実施するときに考慮すべきことは何ですか?
)
print(response)仕組み(Map-Reduce方式):
1. コミュニティレポートを分割
2. 各チャンクから中間回答を生成(Map)
3. 重要ポイントを集約(Reduce)
4. 包括的な回答を生成
出力:(翻訳済み)
買掛金監査を実施する際には、正確性、コンプライアンス、そして潜在的な不正の検出を確保するために、いくつかの重要な要素を考慮する必要があります。以下に、留意すべき重要なポイントを示します。
監査プログラムの理解
監査プログラムは、監査人が財務諸表の正確性を確保するために実施しなければならない具体的な手順とテストを概説しています。財務報告の信頼性を維持するためには、固有のリスクに対処し、様々なテスト手法を取り入れることが不可欠です[データ:レポート(15、4、14、1、5)]。
フォレンジック・アカウンタントの役割
フォレンジック・アカウンタントは、買掛金監査プロセスにおいて重要な役割を果たします。彼らは財務書類や取引を分析し、不正行為を示唆する可能性のある不一致を発見します。彼らの専門知識は、財務報告の完全性と透明性を維持するために不可欠な、様々な手法を適用して財務データの異常を検出することを可能にします[データ:レポート(13、2)]。
固有リスクの考慮事項
固有リスク(IR)は、監査プロセスにおける重要な要素です。これは、内部統制外の要因により財務諸表に重大な虚偽記載が生じるリスクを指します。内部統制を認識することで、監査人は特定の脆弱性に対処するための手続を調整することができ、監査全体の有効性を高めることができます[データ:報告書(15、4)]。
法的基準の遵守
法的基準の遵守を確保することは、買掛金監査において重要な考慮事項です。フォレンジック・アカウンタントは、財務慣行が確立された法令を遵守していることを確認する上で重要な役割を果たします。これは、財務上の不正行為を防止し、社会的信頼を維持するために不可欠です[データ:報告書(13)]。
不正検出のための方法論
監査プロセスにおいて、様々な方法論を活用することが重要です。フォレンジック・アカウンタントは、ベンフォードの法則などの手法を用いてパターンを分析し、不正の兆候を検出します。この統計原理は、不正操作や不正を示唆する可能性のある不規則性を特定し、監査の有効性を高めるのに役立ちます[データ:報告書(13)]。
リスク軽減戦略
監査中の不正行為を防止するための手順の設計と実施において、フォレンジック会計士が果たす積極的な役割は見過ごすべきではありません。このアプローチは、財務リスクの軽減と内部統制の強化、ひいては財務の健全性の確保を目指す組織にとって極めて重要です[データ:報告書(13)]。
情報技術の統合
監査プロセスへの情報技術(IT)の統合は、監査の有効性に大きな影響を与えます。ITは、監査人が財務情報を評価する能力を高めるリアルタイムのデータと分析ツールを提供することで、現代の監査実務において不可欠な要素となっています[データ:報告書(15、4)]。
規制枠組み
2001年会社法やオーストラリア証券投資委員会(ASIC)の役割など、監査を規制する規制枠組みを理解することは非常に重要です。これらの規制は、監査人の責任を概説し、財務報告基準の遵守を確保します。これは、金融システムの健全性を維持するために不可欠です[データ:報告書(16、4)]。
結論
まとめると、買掛金監査を実施するには、監査プログラム、フォレンジック会計士の役割、固有のリスク、法的基準の遵守、不正検出の方法論、リスク低減戦略、IT統合、そして規制枠組みについて包括的な理解が必要です。これらの要素を考慮することで、監査人は監査の有効性を高め、財務報告全体の整合性に貢献することができます[データ:レポート(15、4、14、1、5、13、2、16、その他)]。
仕組み(エンティティ中心の検索):
1. 質問に関連するエンティティを特定
2. 関連する関係性・属性・ドキュメントを取得
3. グラフ構造をたどって情報収集
4. 優先順位付けして回答生成
例: 「ACFEとは?」「Joseph Wellsの詳細は?」
2. Local Search(ローカル検索)
用途: 特定エンティティの詳細な質問
仕組み(エンティティ中心の検索):
1. 質問に関連するエンティティを特定
2. 関連する関係性・属性・ドキュメントを取得
3. グラフ構造をたどって情報収集
4. 優先順位付けして回答生成
例: 「ACFEとは?」「Joseph Wellsの詳細は?」
使い分け
Global:「全体的に〜」「主な〜」
Local:「XXXとは?」「XXXの詳細は?」
10 プロンプトカスタマイズ
GraphRAGのPrompt Tuningは、LLMへの指示文をデータやドメインに合わせて最適化する仕組みで、まずはデフォルトプロンプトでそのまま動かすことができる。Auto Tuningでは、実際のデータを使ってLLMが自動でプロンプトを調整し、精度を上げ、Manual Tuningでは、ユーザーがテンプレートを直接編集して細かくカスタマイズできる。
この3段階(デフォルト → 自動 → 手動)で、汎用から専門まで柔軟に対応可能。
11 まとめ
GraphRAGの本質
GraphRAGは、テキストを理解して知識グラフを構築し、構造的な検索を可能にする次世代RAGシステム。従来のRAGが文章を単純に分割してベクトル化するのに対し、GraphRAGは「誰が・何を・どうした」という関係性を理解してから埋め込む。
適用場面
向いている:
- 複雑な関係性の理解(監査、法務、医療)
- 大規模データの俯瞰分析
- 「なぜ」「どのように」という深い質問
向いていない:
- 単純な事実検索
- リアルタイム更新が必要
- 小規模データ(コスト過多)
カスタマイズポイント
- Prompt Tuning: デフォルト → Auto → Manual
- Entity Types: ドメインに合わせて調整
- Community Level: 質問の抽象度で選択(0-2)
結論: GraphRAGは理解→構造化→検索という流れで、従来RAGより賢い情報取得を実現する。初期コストは高いが、複雑なドメインでは圧倒的な価値を提供。
参考資料





