データベース正規形徹底解説:1NFからBCNFまで

本記事では、データベースの正規化について、その重要性から各正規形(1NF、2NF、3NF、BCNF)の具体的なルールと目的を解説し、データ整合性とパフォーマンスのバランスを考慮した最適な設計の考え方を提案します。
目次
はじめに:データベース正規化の重要性
現代ビジネスにおいて、データは意思決定に欠かせません。そのデータを効率的かつ信頼性高く管理するために、「リレーショナルデータベース(RDB)」と「正規化」は非常に重要です。ここでは、RDBの基本と、なぜ正規化が必要なのかを解説します。
リレーショナルデータベースとは?
RDBは、データを「テーブル」(行と列の表)で整理するデータベースです。
各テーブルはビジネス上の特定の対象(エンティティ)を表し、行は個々のデータ、列はデータ項目です。RDBは、SQL(構造化クエリー言語)を使ってデータの保存、検索、管理を効率的に行います。RDBの信頼性を支えるのは、ACID特性(原子性、一貫性、独立性、永続性)です。この厳格なルールにより、RDBは金融システムなど、高い信頼性が求められる分野で広く使われています。
なぜ正規化が必要なのか?目的とメリット
データベースの「正規化」とは、データの重複(冗長性)をできるだけなくし、矛盾なく効率的にデータを扱えるようにデータベースを設計するプロセスです。
正規化によって得られるメリットは多くあります。まず、データの整合性を確保し、矛盾を防ぎ、常に一貫した状態を保ちます。これは、データの更新、挿入、削除時に発生しうる「異常」(更新異常、挿入異常、削除異常)といった具体的なリスクを避ける上で非常に重要です。
次に、データを適切に分割・整理することで、データ管理が簡単になります。さらに、データの変更が必要になった際、影響を受ける範囲を限定できるため、修正の手間を減らし、エラーの発生を抑え、データを柔軟に変更できるようになります。
加えて、無駄なデータ重複を抑えることで、ストレージの利用効率が向上し、データ量の削減だけでなく、バックアップや復旧にかかる負担も減らせます。これは、データベースの運用コスト削減にもつながります。
正規化の基本概念:キーと関数従属性
正規化の各ステップを理解する上で、最も基本となるのが「キー」と「関数従属性」です。これらの概念を正確に把握することが、なぜ特定のデータを分割するのか、その論理的な理由を理解する鍵となります。
キーとは?
リレーショナルデータベースにおける「キー」とは、テーブル(表)内の各行(レコード)を特定したり、テーブル同士の関連付けを行ったりするために使われる、一つまたは複数のデータ項目(列)の集まりです。キーはデータベースの整合性(矛盾がないこと)と効率を保つ上で非常に重要な役割を果たします。
主なキーの種類は以下の通りです。
- スーパーキー (Super Key): テーブル内の各行を「一意に」識別できる属性の集まりです。例えば、
{社員ID, 氏名, 住所}はスーパーキーになり得ます。ただし、その一部だけでも識別できるかもしれません。 - 候補キー (Candidate Key): スーパーキーの中で、最も少ない属性で構成され、かつ各行を「一意に」識別できる属性の集まりです。つまり、候補キーからどの属性を一つでも削除すると、一意に識別できなくなります。テーブルには複数の候補キーが存在することもあります。例えば、社員テーブルで「社員ID」と「メールアドレス」がそれぞれユニークな値を持つ場合、
{社員ID}も{メールアドレス}も候補キーになり得ます。 - 主キー (Primary Key): テーブルの設計者が、複数の候補キーの中からそのテーブルの代表として選び、行を一意に識別するために使うキーです。主キーとして選ばれた属性(または属性の集まり)は、以下の特徴を持ちます。
- 一意性: テーブル内の各行を必ず「一意に」識別できる。
- 非NULL性: NULL値(何も入っていない状態)を持つことはできない。 テーブル内で主キーは一つだけです。
これらのキーは、データの正確性を保証し、効率的なデータ検索やテーブル結合を可能にするための土台となります。正規化のプロセスでは、特に候補キーや主キーの考え方が深く関わってきます。
関数従属性とは?
関数従属性(Functional Dependency)とは、リレーショナルデータベースのテーブルにおいて、ある属性(データ項目、またはその集まり)の値が決まると、他の属性(またはその集まり)の値が「一意に」決まるという性質を指します。ここでいう「関数」は数学的な規則性ではなく、単に「一つ決まるともう一つが自動的に決まる」という関係を意味します。この関係は「X が Y を決定する」と表現され、X → Y と表記されます。
例:
社員ID → 氏名(社員IDが決まれば、氏名が一意に決まる)郵便番号 → 住所(郵便番号が決まれば、住所が一意に決まる)
正規化、特に第二正規形(2NF)以降の正規化は、この属性間の関数従属性を分析し、整理することで行われます。X → Y の関係において、X を「決定項(Determinant)」(Yを決定する側)、Y を「従属項(Dependent)」(Xに決定される側)と呼びます。
この「一意に決まる」という厳密な関係は、単なる関連性や傾向ではなく、決定的な結びつきを示します。例えば、「社員ID」が決まれば「氏名」が一意に決まる関係は成立しますが、同姓同名がいるため、「氏名」が決まれば「社員ID」が一意に決まる関係は通常成立しません。この「方向性」と「一意性」を理解することが、第二正規形や第三正規形でどのデータを分離すべきかを判断する際の論理的な理由となります。この概念を深く理解せずにテーブルを分割しようとすると、その根拠が曖昧になってしまう可能性があります。
第一正規形 (1NF) を理解する
第一正規形は、データベース正規化の最初の、そして最も基本的なステップです。データの「原子性」(これ以上分解できないこと)を確保し、テーブルの基本的な構造を整えることを目的とします。
定義とルール
第一正規形(1NF)は、データベースの各テーブルが以下の要件を満たす状態を指します。
- 各列が単一の値を持つ(原子性): 各セル(フィールド)には、リストや配列のように複数の値を含まず、一つだけの、それ以上分割できない値が入っていること。
- 繰り返しグループが存在しない: テーブル内に同じ種類のデータが複数の列として繰り返されていないこと(例:「電話番号1」「電話番号2」といった列が存在せず、各電話番号が独立した行として扱われるべきです)。 1NF化は、テーブルの「横方向の重複」をなくす方法とも言えます。これにより、データの重複や矛盾を防ぎ、データベースの基本的な構造が整います。また、合計金額のように計算で求められる列は、通常、テーブルには記録せず、必要に応じて計算で出すべきとされます。
この1NFは、データの矛盾を防ぐだけでなく、データベースの「利用しやすさ」に直接つながる最も基本的なルールです。例えば、カンマ区切りで複数の電話番号が入力されているような非1NFのデータでは、特定の電話番号を効率的に検索したり、インデックスを適切に設定したりするのが難しくなります。これにより、SQL(データベースを操作する言語)の利用が複雑になり、データ分析の速度も著しく低下してしまいます。1NFを満たすことで、データの検索や分析の効率が向上します。
具体例で学ぶ1NF化
以下に、第一正規形を満たしていないテーブルと、それを1NF化した例を示します。

このテーブルでは、「部活名」の列に複数の値がカンマ区切りで含まれており、繰り返しグループが存在します。
非1NFのテーブルを1NFに変換するには、各セルが単一の値を持つようにデータを分割し、繰り返しグループを排除します。
この例では、生徒と部活の情報を分離し、「生徒部活テーブル」で各生徒の部活を独立した行として表現しています。これにより、各セルが単一の値を持つようになり、繰り返しグループが排除されます。
第二正規形 (2NF) へのステップ
第二正規形は、第一正規形を基盤とし、主キーが複数の項目で構成されている場合に生じるデータの重複(冗長性)を排除することを目的とします。
定義とルール
第二正規形(2NF)は、第一正規形(1NF)を満たした上で、部分関数従属性を排除した状態を指します。この正規形は、特に主キーが複数の属性(列)で構成される「複合主キー」である場合に重要となります。2NFの目的は、主キーの一部だけで決まってしまう他の列(非キー属性)をなくし、「非キー属性が主キー全体に完全に依存していること」を保証することです。
部分関数従属性とは?
部分関数従属性とは、テーブルの複合主キーを構成する一部の属性だけで、他の非キー属性の値が一意に決まってしまう関係のことです。例えば、複合主キーが {A, B} で、非キー属性 C が A だけで決まる場合(A → C)、C は複合主キー {A, B} に対して部分関数従属していると言えます。この状態だと、主キーの一部が変わるだけで関連する非キー属性が重複する可能性があります。
具体例で学ぶ2NF化
以下に、第二正規形を満たしていないテーブルと、それを2NF化した例を示します。
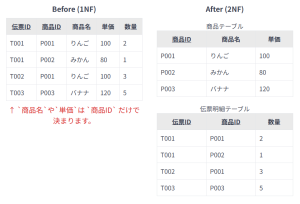
このテーブルでは、{伝票ID, 商品ID} が複合主キーです。 しかし、「商品名」や「単価」は 商品ID だけで決まります。これは、複合主キーの一部である 商品ID に部分関数従属しています。このため、同じ「商品ID」(例えばP001)が異なる伝票に登場するたびに、「りんご」「100」という情報が繰り返し記録されています。
上記の「伝票明細テーブル」の例では、商品名や単価が商品IDのみに依存し、複合主キー全体には依存しません。これは、1つのレコード内に「伝票明細に関する事実」(数量)と「商品に関する事実」(商品名、単価)という異なる種類の情報が混在していることを意味します。このようなデータの重複を解消するため、2NFはこれらの事実をそれぞれのテーブルに分離します。
テーブルを2NFに変換するには、部分関数従属している属性を別のテーブルに切り出します。
この正規化により、商品に関する情報が独立した「商品テーブル」に分離され、伝票明細テーブルには複合主キーに完全に依存する「数量」のみが残ります。これにより、データの重複が大幅に削減されます。2NFは「非キー属性が候補キー全体に完全に依存していること」を保証します。つまり、非キー属性が主キーの「一部」ではなく、「全体」に依存しなければならないという、データ間の論理的な関係を厳密に定義します。これにより、データベースの設計はより論理的に一貫性のあるものとなり、異なる種類の情報が不適切に結合されることを防ぎます。
第三正規形 (3NF) でさらに洗練
第三正規形は、第二正規形をさらに洗練させ、主キー以外の項目間の間接的な依存関係(推移的関数従属性)を排除します。
定義とルール
第三正規形(3NF)は、2NFを満たした上で、非キー属性間の推移的関数従属性を排除することを目的とします。つまり、主キー以外の属性が、主キー以外の別の属性を介して主キーに依存する関係(間接的な依存関係)を解消します。
推移的関数従属性とは?
推移的関数従属性とは、テーブルにおいて、複数の関数従属関係が段階的に成り立つ関係です。具体的には、属性 X から Y が一意に決まり(X → Y)、さらに Y から Z が一意に決まる(Y → Z)場合、Z は X に「推移的に」従属していると言います(X → Z)。このとき、Z は主キー X に直接依存するのではなく、非キー属性 Y を介して間接的に決定されています。このような状態はデータの重複や矛盾を引き起こしやすいため、正規化のプロセスで解消が必要です。
具体例で学ぶ3NF化
以下に、第三正規形を満たしていないテーブルと、それを3NF化した例を示します。
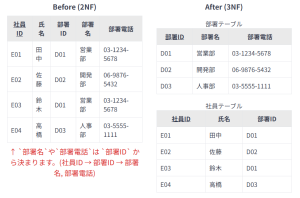
このテーブルでは、社員ID が主キーです。社員ID → 部署ID の関係が成り立ちます。 しかし、「部署ID」が決まれば「部署名」と「部署電話」が一意に決まります(部署ID → 部署名, 部署電話)。このとき、「部署名」や「部署電話」は 社員ID に直接依存するのではなく、「部署ID」を介して間接的に依存しています(社員ID → 部署ID → 部署名, 部署電話)。これが推移的関数従属性です。同じ部署の社員が複数いる場合、部署名や部署電話が重複して記録され、部署の情報が変更された際に複数の行を更新する必要が生じます。
この例における部署名や部署電話は、部署に関する事実であり、社員IDに直接関する事実ではありません。もし複数の社員が同じ部署にいる場合、その部署の部署名や部署電話は各社員のレコードで重複して記録されます。その部署の情報が変わった場合、その部署に属する全ての社員レコードを更新しなければならず、抜け漏れが生じると矛盾が発生します。3NFはこのような「事実に関する事実」(間接的な依存関係)を分離することで、更新の柔軟性を高めます。
テーブルを3NFに変換するには、推移的関数従属性を持つ属性を別のテーブルに切り出します。
この正規化により、部署に関する情報が独立した「部署テーブル」に分離され、社員テーブルからは「部署名」と「部署電話」が削除され、「部署ID」が外部キーとして残ります。これにより、データの重複がほとんどなくなり、更新時の矛盾リスクが低減します。3NFは「さらに分離できる部分を分離する」ことで、より小さく、焦点を絞ったテーブルを作成します。結果として、よりモジュール化され、柔軟性の高いデータベース設計につながり、将来的な拡張や変更への対応が容易になります。
ボイス・コッド正規形 (BCNF) の厳格なルール
ボイス・コッド正規形(BCNF)は、第三正規形よりもさらに厳格な条件を持つ正規形であり、特定のケースで3NFでは捉えきれないデータの重複を排除します。
定義と3NFとの違い
BCNFは、リレーショナルデータベース設計における正規化の一形態であり、第三正規形(3NF)よりも厳格な条件を持ちます。BCNFの主なルールは、「テーブル内のすべての決定因子(他の属性を一意に決定する属性または属性の集合)が、そのテーブルの候補キーでなければならない」というものです。つまり、ある項目が他の項目を決定する力を持っているなら、その項目自体がそのテーブルを識別できる最もコンパクトな「候補キー」であるべきだ、という考え方です。これにより、テーブル内のすべてのデータが「一意に」識別される必要性を強調します。
3NFは「主キー以外の属性間の間接的な依存関係」の排除に焦点を当てます。しかし、BCNFは、決定因子が主キーではない項目である場合や、複数の候補キーが複雑に重なり合っている場合に生じるデータの重複も排除します。つまり、BCNFはデータ項目間の依存関係に、より強い制約を課しています。これは、3NFが非キー属性間の推移的関数従属性に焦点を当てるのに対し、BCNFは、たとえ決定因子が主キー以外の項目であっても、それが他の項目を決定する能力を持つならば、その決定因子自体が候補キーであるべきだという、より深いデータの整合性を追求していることを示します。
BCNFが必要なケースと具体例
BCNFは、3NFでは解決できない、より複雑な関数従属性のパターンに対応するために導入されました。これは主に、テーブル内に複数の候補キーが存在し、それらが複雑に絡み合っている場合に発生します。
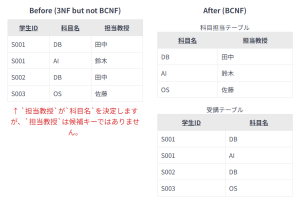
【前提条件】
・学生は複数の科目を受講できる。
・科目は複数の学生に受講される。
・各科目は特定の教授が担当する(例: DBは田中教授のみ)。
・各教授は特定の科目のみを担当する(例: 田中教授はDBのみ)。
【解説】
・主キーは {学生ID, 科目名} です。
・科目名 → 担当教授 という関数従属性が存在します(各科目は特定の教授が担当するため)。
・担当教授 → 科目名 という関数従属性も存在します(各教授は特定の科目のみを担当するため)。
・このテーブルは3NFを満たしています。なぜなら、担当教授 は非キー属性であり、科目名 は非キー属性ですが、科目名 は主キーの一部であるため、推移的関数従属性ではありません。また、担当教授 は主キーの一部にも、主キー全体にも依存せず、科目名 にのみ依存しています。
・しかし、BCNFのルール「すべての決定因子が候補キーでなければならない」に照らすと、科目名 と 担当教授 は互いに決定因子ですが、どちらもこのテーブルの候補キー({学生ID, 科目名})ではありません。したがって、これはBCNFに違反しています。
→データの重複:科目名 と 担当教授 のペア(例:「DB, 田中」)が、その科目を履修する学生の数だけ繰り返し記録されます。
この例は、科目名(主キーではない項目)が担当教授(主キーではない項目)を決定し、かつ担当教授が科目名を決定するような相互依存関係がある場合、3NFは満たしてもBCNFは満たさないことを示しています。BCNFはこのような複雑な依存関係を分離し、データの重複と更新異常の可能性をさらに排除します。これは、3NFが見落とす「主キーではない項目が候補キーの一部を決定する」という微妙な重複を解決するものです。
このテーブルをBCNFに変換するには、科目名と担当教授の間の相互依存関係を独立したテーブルに分離します。
正規化により、科目名と担当教授の間の相互依存関係が独立した科目担当テーブルに分離されます。これにより、科目名と担当教授のペアの重複が解消され、より厳密なデータ整合性が実現されます。
BCNFは理論上、依存関係に基づく正規化の最高レベルを提供しますが、その適用はデータの完全な整合性と設計の複雑さの間の「トレードオフ」を伴います。正規化全般のデメリットとして「複雑さ」や「パフォーマンス低下」が挙げられることから、BCNFの適用は、より多くのテーブル分割と複雑な結合操作を伴う可能性が高いと推測されます。多くの実用的なシステムが3NFで設計を止めるのは、このバランスを考慮した結果であり、BCNFの適用は、極めて高いデータ整合性が要求される特定のケースに限定されるべきだからです。
正規化のデメリットと非正規化の選択
正規化は多くのメリットをもたらしますが、その適用にはマイナス面も存在します。ここでは、正規化のデメリットと、あえて正規化をしない「非正規化」という選択肢について解説します。
パフォーマンス低下とクエリの複雑化
正規化の最も代表的なデメリットは、パフォーマンスの低下です。データを複数のテーブルに分割することで、特定の情報を取得するために複数のテーブルを結合する「JOIN」操作が頻繁に必要になります。JOIN操作は、特に大量のデータや複雑なクエリの場合に処理時間を長くし、データベースにかかる負担を増加させます。
これにより、データの検索や操作(クエリ)が複雑になり、開発者がデータベースについて深い知識を持つ必要が生じます。また、正規化されたデータベースは、非正規化されたデータベースよりも設計が厳密になるため、管理やメンテナンスも複雑になりがちです。正規化は「パフォーマンスが少し落ちてしまうことよりも、データの矛盾がない状態を維持することや、データの変更に柔軟に対応できることを優先する作業」と言えます。この言葉は、正規化がもたらすパフォーマンスへの影響を認識しつつも、データの品質を最優先する設計思想を示しています。
非正規化とは?メリット・デメリット
「非正規化(Denormalization)」とは、データベースの読み込み速度を上げるために、意図的にデータの重複を許容し、正規化されたデータベースの構造をあえて崩す設計手法です。非正規化は、正規化されたデータベース上に重複したデータを作成することで、データの更新や挿入の速度は遅くなる代わりに、データの読み込み速度を速めることを目指します。
非正規化のメリット:
- 読み込みパフォーマンスの向上: データの重複を許容することで、テーブルの結合(JOIN)の回数を減らし、データ検索の実行速度を向上させます。特に、頻繁にアクセスされる集計結果や、複雑な結合が必要なデータを一つのテーブルにまとめておくことで、リアルタイム処理の負担を軽減できます。
- クエリの単純化: 複数のテーブルからの情報を1つのテーブルにまとめることで、クエリがシンプルになり、開発の効率が向上します。
非正規化のデメリット:
- データの重複増加: 最も明らかなデメリットであり、同じデータが複数箇所に存在するため、ストレージ容量が余分に必要になる可能性があります。
- データ不整合のリスク: 重複したデータが存在するため、更新や削除の際にすべての重複箇所を正確に修正しないと、データ間に食い違い(不整合)が生じるリスクが高まります。特に、更新漏れは深刻な問題を引き起こす可能性があります。
- メンテナンスコストの増加: データの複雑さと重複が増すため、データベースの保守や管理が難しくなり、コストが高くなることがあります。
- 挿入・更新コストの増加: データの重複により、新しいデータを追加したり、既存のデータを更新したりする際に複数の箇所を操作する必要が生じ、書き込みパフォーマンスが低下する可能性があります。
いつ非正規化を検討すべきか
正規化と非正規化は、パフォーマンスとデータの矛盾がない状態(整合性)の間でバランスを取る関係にあります。最適なデータベース設計は、アプリケーションの目的や利用状況に応じて、このバランスを適切に取ることが重要です。
正規化と非正規化は、データの読み込み速度と、データの書き込み・更新時の矛盾がない状態という、データベース設計における根本的な選択を迫ります。正規化はJOINが増えることによるパフォーマンス低下を招く一方、非正規化は読み込みパフォーマンスを向上させるものの、データの重複と矛盾のリスクを伴います。最適な設計は、アプリケーションの利用状況(読み込みが多いか、書き込みが多いか)、データの重要性、許容できるパフォーマンスのレベルによって異なります。
非正規化を検討すべき主なケースは以下の通りです。
・読み込みパフォーマンスが極めて重視される場合
・複雑なJOINが頻繁に発生し、それがパフォーマンスのボトルネックになっている場合
・データ構造が比較的安定しており、更新の頻度が低い場合
・特定のレポートやダッシュボードのために最適化されたデータが必要な場合
ただし、非正規化はデータ整合性への影響が大きいため、慎重な判断と、矛盾を防ぐためのアプリケーション側での厳密な制御が必要です。
RDBの正規化は、データの重複を最小限に抑え、矛盾がない状態を維持するための非常に重要な設計手法です。第一正規形からボイス・コッド正規形に至る各段階は、特定の種類のデータの依存関係を体系的に排除し、データの一貫性と効率的な管理を目指します。
しかし、正規化しすぎると、テーブルの分割によるJOINの増加を招き、データの検索や操作が複雑になったり、パフォーマンスが低下したりする可能性があります。非正規化は、特定の読み込みパフォーマンスの要件を満たすための有効な手段ですが、データの重複増加とそれに伴う矛盾リスクの管理という課題を伴います。したがって、どの正規形まで適用するか、あるいは非正規化を導入するかは、業務の目的、データの特性、予算、そしてシステムの利用パターンを総合的に判断して決定されるべきです。
まとめ:最適なデータベース設計のために
RDBの正規化は、データの重複を最小限に抑え、矛盾がない状態を維持するための非常に重要な設計手法です。第一正規形からボイス・コッド正規形に至る各段階は、特定の種類のデータの依存関係を体系的に排除し、データの一貫性と効率的な管理を目指します。
しかし、正規化しすぎると、テーブルの分割によるJOINの増加を招き、データの検索や操作が複雑になったり、パフォーマンスが低下したりする可能性があります。非正規化は、特定の読み込みパフォーマンスの要件を満たすための有効な手段ですが、データの重複増加とそれに伴う矛盾リスクの管理という課題を伴います。したがって、どの正規形まで適用するか、あるいは非正規化を導入するかは、業務の目的、データの特性、予算、そしてシステムの利用パターンを総合的に判断して決定されるべきです。
これまで説明してきた正規形を下の表にまとめました。ぜひ参考にしてください。






