【適合率と再現率はもう迷わない!】評価指標を解説

この記事では、二値分類を中心に精度評価の全体像を整理しつつ、特に「適合率(Precision)」と「再現率(Recall)」の違いを忘れない覚え方をマスターできます。
イントロダクション
機械学習モデルの性能評価で必ず登場するF1スコアなどの評価指標。「適合率と再現率の違いがいつも混乱する…」そんな悩みを解決します。
この記事では、二値分類を中心に精度評価の全体像を整理しつつ、特に「適合率(Precision)」と「再現率(Recall)」の違いを忘れない覚え方をマスターできます。
重要な基礎:混同行列を作れば9割わかる!
二値分類では、予測と実際の組み合わせを 混同行列(Confusion Matrix) に並べます。
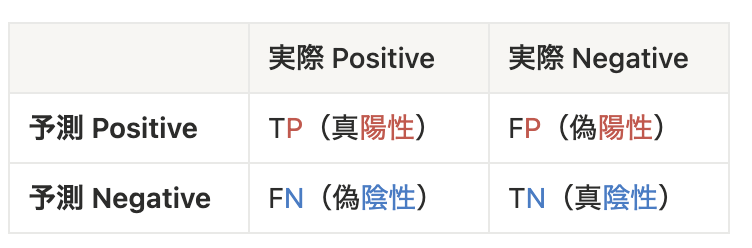
- TP(True Positive): 正しく陽性と当てた
- FP(False Positive): 本当は陰性なのに陽性と誤判定(誤検出・誤報)
- FN(False Negative): 本当は陽性なのに陰性と誤判定(見逃し)
- TN(True Negative): 正しく陰性と当てた
これから紹介する評価指標は、すべて混同行列から導かれます!
主要な評価指標
正解率(Accuracy)
Accuracy = (TP + TN) / (TP + FP + FN + TN)
- 「全体のうち、正しく予測できた割合」
- シンプルですが、不均衡データ(陽性が希少など)では注意が必要
- 例:100人中1人だけが病気の場合、全員を「健康」と予測しても正解率99%になってしまいます。しかし病気の人を一人も発見できていないため、実用上は価値がありません。これを”Accuracyパラドックス”(見せかけの高精度)と呼びます。
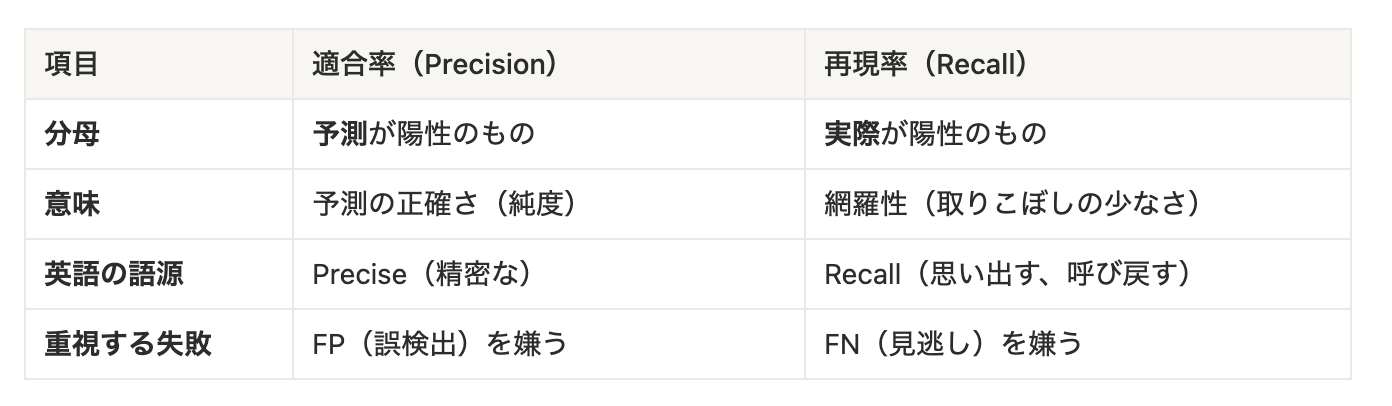
適合率(Precision)=「陽性と言ったものの純度」
Precision = TP / (TP + FP)(分母:予測が陽性)
- 「モデルが陽性と予測したもののうち、実際に陽性だった割合」
- 適合率が高い = 予測の「的中率」が高い = 誤報が少ない
- 例:迷惑メール判定 → 迷惑扱いしたメールの外しが少ないか(誤爆したくない)
再現率(Recall )=「本当の陽性をどれだけ拾えたか」
Recall = TP / (TP + FN)(分母:実際が陽性)
- 「実際に陽性のもののうち、モデルが正しく見つけた割合」
- 再現率が高い = 「網羅率」が高い = 見逃しが少ない
- 例:疾病スクリーニング → 病気の人を取りこぼさないか(見逃したくない)
2つの指標は 混合行列のどこを分母にするか の違いです。
F1スコア
F1 = 2 × (Precision × Recall) / (Precision + Recall)
- 「適合率と再現率の調和平均」で、バランスを重視
- なぜ調和平均?
- 単純平均では片方が極端に低くても高得点になってしまうから。
- 例:Precision=100%、Recall=10% → 単純平均55%、F1スコア18%
- 調和平均は極端に小さい値に引きずられる特徴があるため、両方が高くないと高得点にならない!
特異度
Specificity = TN / (TN + FP)
- 陰性を正しく陰性と判定できた割合(= 1 – 偽陽性率)
- 「陰性の再現率」とも言え、医療検査などで、再現率(感度)とペアで報告されることが多いです。
適合率、再現率を一生忘れない覚え方
暗記フック
「PはPrediction、RはReality」
- Precision は Prediction(予測)の P → 分母は「予測陽性」
- Recall は Reality(現実)の R → 分母は「実際の陽性」
適合率と再現率の違い対比表
PrecisionとRecallのトレードオフ
適合率と再現率は一般にトレードオフの関係にあります。モデルの判定基準(しきい値)を調整することで、どちらを重視するかを変えられますが、一方を上げると他方が下がる傾向があります。
おわりに
まとめ
✅ PはPrediction → Precisionは分母が予測陽性。純度。
✅ RはReality → Recallは分母が実際の陽性。取りこぼし。
✅ F1はPとRの調和平均:どちらかが低いと下がる。
✅ トレードオフを理解する:閾値調整で一方が上がると他方が下がる
その他にも、ROC-AUCやRMSE、寄与率などの評価指標については、また別のブログでご紹介します!





