統計的仮説検定|メリットと種類について解説!

「先月の来店数が1000人で、今月は1200人になった!」
これを聞いて、「今月の施策が上手くいって嬉しい!」と思ってしまうのは危ないです。
なぜならその月は偶然来店数が増えただけで、実施した施策の効果とは言い切れないからです。
データの差分だけを考えて結論を出してしまうのは、主観的でありデータドリブンな判断とは言えません。
しかし統計学を利用すると、偶然性を排除した信頼できる結果であるのかを確認することができます。
そこで今回は、データ分析の信頼性を上げる、統計的仮説検定について解説していきます。
そもそも統計的仮説検定とは?
総務省が公開している「統計的推定と統計的仮説検定」によると統計的仮説検定とは『母集団に関するある仮説が統計学的に成り立つか否かを、標本のデータを用いて判断すること』としています。
https://www.stat.go.jp/naruhodo/11_tokusei/kentei.html
もう少し易しく換言すると『統計学を使って、データ分析の結果が偶然ではないことを確かめること』となります。
データ分析は、一言で言うと分類して比較することです。
しかしその比較結果が偶然による誤差ではないことを示さなければ、主観的で信頼性の低いデータ分析と言わざるをえません。
例えば、広告でA/Bテストを実施した場合を考えて見ましょう。
クリエイティブを変えた広告AとBのCTR が0.2%違う場合、誤差と言えるでしょうか。
人によって意見が別れると思います。
データ分析をして明らかになった差異を重要と判断することは、実は主観的であり信頼できませんよね。
統計的仮説検定を実施することで、検証する数値や事象の存在を何%で信頼できるのかを確認することが出来ます。
これにより、数値や事象が偶然であるかを経験や直感ではなく、確率に基づいて数学的に議論できることは、ビジネスにおけるデータ分析であっても重要です。

統計的仮説検定のメリット
それでは、統計的仮説検定のメリットとは何でしょうか?
メリットは大きく分けて3つありますので、1つずつ解説していきます。
1.データ分析の結果の正当性を判断できる
データ分析は仮説を持って分析をすることが多く、バイアス(偏向)が加わった上でデータを見てしまうので、偶然生じた結果も望んだ結果として考えてしまうことがあります。
しかし、統計的仮説検定を実施すると、結果が偶然であるのか否かが判断できます。
分析結果の偶然性を疑う依頼者に対して、客観的で信頼性があることを示せるので、ビジネスにおけるデータ分析でも統計的仮説検定は必須と言えるでしょう。
2.少ないデータ量での結果の正当性を確認できる
データ分析では、出来るだけ大量のデータを分析した方が良いとされています。なぜなら、データ数が多ければ多いほど標本分散と母集団の分散との差が少なくなるためです。
しかしながら、データを取得したばかりや集計方法の変更などにより、少ないデータ量でデータ分析をしなければならないケースがあります。
その際に統計的仮説検定を用いると、少ないデータ量を考慮した上で正当性を判断することができます。
大量のデータが貯まるまで効果検証を待つ必要がないので、新規企画やキャンペーンを進める際の意思決定に活用できます。
3.無駄な手間や損失を防げる
データ分析では、ドリルダウン式に深堀していくことが多いです。
つまり、最初の全体的な分析結果に基づいて、更なる分析を行っていきます。
仮に最初の分析結果が偶然であった場合、その後分析を深堀しても有意義な結果は得られません。
それだけではなく、最初の分析結果のバイアスにより間違った分析結果になることも多々あります。
分析の早い段階から統計的仮説検定を行うことで、膨大な時間の浪費や誤った分析結果による損失を防ぐことができます。
統計的仮説検定の種類
統計的仮説検定には様々な種類が存在しますが、メジャーな3つをご紹介します。
・カイ二乗検定
・t検定
・分散分析
まず違いについて解説したのち、それぞれについて解説していきます。
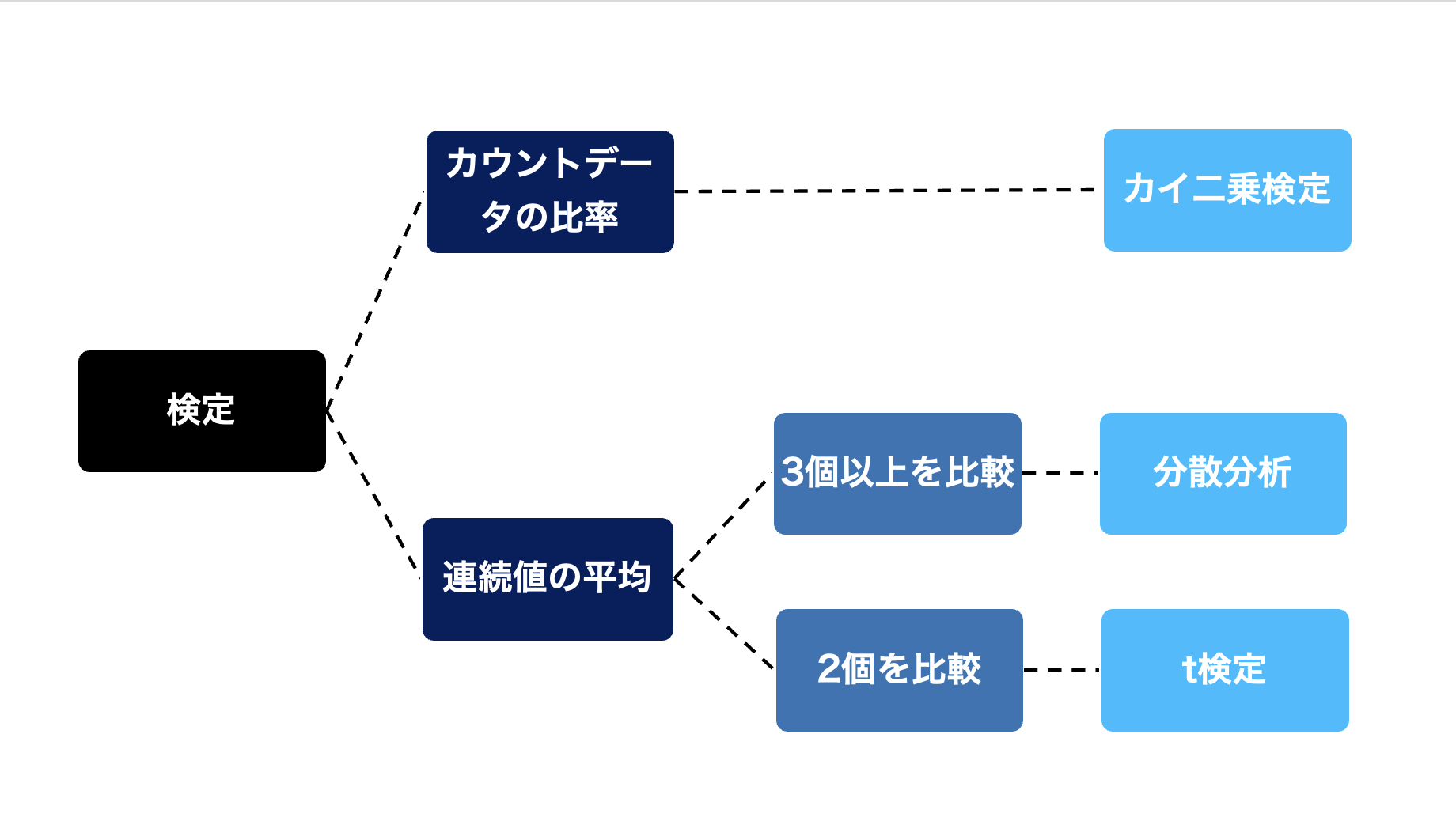
これらの検定手法の違いは、比較したい指標の種類と比較する数に基づきます。
比較したい指標がカウントデータの場合、使用するのはカイ二乗検定です。
比較したい指標が連続値における平均値の場合で、比較対象が2つならばt検定となり、比較対象が3つ以上の場合、分散分析となります。
カイ二乗検定
カイ二乗平均とは、カイ(χ)の二乗平均と呼ばれる確率分布を用いて、連続していないデータ同士を検定するのに利用します。
例えば、アンケートで「新商品を買いたい」「新商品を買いたくない」という項目のデータがこれに相当します。
これを用いることで、アンケートの質問項目の回答が偶然ではないことを示すことが出来ます。
詳しいやり方は、今後記事化していきますが、大まかにやり方を示すと
1.帰無仮説と対立仮説を決定
2.有意水準の決定
3.期待度数を算出
4.カイ二乗値の算出
5.P値の算出
6.仮説の判定
となります。
t検定
t検定とは1908年にゴセットが発表した論文『平均の確率誤差』で紹介されたのが起源となっており、t分布と呼ばれる確率分布を利用します。
検定に用いるデータは、身長や売上額などの連続した値です。
t検定により、選んだサンプルが母平均とズレているのかを確かめることが出来ます。特徴としては、収集したデータの数が少なくても検定が可能であることである。
具体的には、抽出したデータ数(標本サイズ)が6前後で検定が出来ます。
詳しいやり方は、今後記事化していきますが、大まかにやり方を示すと
1.帰無仮説と対立仮説を決定
2.有意水準の決定
3.検定統計量の算出
4.P値の算出
5.仮説の判定
となります。
分散分析
t検定は選んだデータサンプルと母集団など2つのデータ集団の比較でしたが、3つ以上のデータ集団の比較に用いるのが分散分析で、F分布と呼ばれる確率分布を利用します。
分散分析では、変数の各水準の母平均に違いがあるかどうかを分散の大きさの違いで検定を行ないます。
一つ注意として、分散分析では集団間の差異が偶然ではないことを確かめることは出来ますが、どれとどれが異なっているのかを示すには多重分析を行わないといけません。
詳しいやり方は、今後記事化していきますが、大まかなやり方は、t検定と同様となります。
統計的仮説検定のまとめ
統計的仮説検定はデータ分析の信頼性を客観的に述べるのに適しています。
ビジネスにおけるデータ分析の価値は、分析結果で意思決定を支援することですので、その分析結果が本当に正しいのかを合わせて提示することは依頼者に安心感を与えるとともに分析者の信頼にも繋がります。
また、データ分析の途中でも仮説に分析結果に対して検定を実施することで、誤った分析結果に基づいた分析をしてしまう無駄な手間や誤った分析結果に到達することを避けることが出来ます。
もちろん、扱うデータの種類や検定項目によって検定方法が異なったり、統計的仮説検定を行うには統計学の理解も求められたりとハードルが高いかもしれませんが、データ分析者には必須のスキルですので、ぜひ習得、実践してみてはいかがでしょうか?




