DataikuでPCA(主成分分析)をやってみた

DataikuでPCA(主成分分析)をやってみました!Irisデータセットを使った手順を画像付きで解説します!DataikuでPCAを試すかたの参考になれば幸いです。
はじめに
主成分分析(PCA)とは
主成分分析(PCA)とは、多次元のデータをより少ない次元に圧縮する手法です。データの情報をできるだけ保ちながら、複雑なデータをシンプルに表現することができます。 例えば今回使うIrisデータセットは4つの特徴量(sepal_length・sepal_width・petal_length・petal_width)を持っています。4次元のデータは人間の目では視覚化できませんが、PCAを使うことで2次元の散布図として表現できるようになります。
PCAが使われる場面
可視化:高次元データを2〜3次元に落として目で確認したいとき
前処理:機械学習モデルに入力する前に特徴量を減らしたい時
ノイズ除去:重要度の低い特徴量を取り除きたいとき
→今回は可視化を目的としてPCAを行います
なぜDataikuで行うのか
DataikuはノーコードでPCAを実行できるため、Pythonを書かなくてもすぐに試せます。
環境設定
ツール:Dataiku DSS
データセット:Iris Dataset
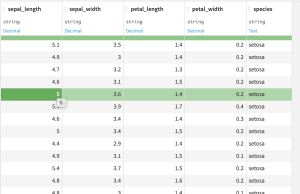
データ概要
Irisデータセットはアヤメの花のデータで、以下の4つの特徴量と品種ラベルからなります。
実装手順
手順1:Irisデータセットを取り込む
データセットを開き、上部メニューの「統計」タブをクリックします。
手順2:「+ NEW CARD」からPCAを選択
右上の「+ NEW CARD」をクリックすると、分析の種類を選ぶ画面が表示されます。
ここで「Multivariate analysis」を選択します
続いてPrincipal Component Analysis(PCA)を選択し、「CREATE CARD」をクリックします。
手順3:変数を選択 左側の変数リストから
sepal_length・sepal_width・petal_length・petal_widthの4つを真ん中にドラッグします。(speciesは品種ラベルなので除外します。)
右側のOptionsはデフォルトのまま(Scree plot・Scatter plot・Loading plot・Principal componentsにチェック)でCREATE CARDをクリックします。
結果
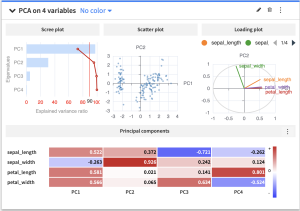
Scree plot
PC1だけで約73%の分散を説明しており、PC1とPC2の2つで約96%をカバーできています。つまり4次元のデータを2次元に削減しても、ほぼ情報が失われないことがわかります。
Scatter plot
PC1とPC2の2軸でデータを散布図にしたものです。データのかたまりが視覚的に確認できます。
Loading plot
petal_lengthとpetal_widthがPC1に強く影響しており、sepal_widthはPC2に強く影響していることがわかります。花びらのサイズがアヤメの品種を分類する上で重要な特徴量であることが示唆されます。
Principal components
各主成分に対する各変数の寄与度が数値で確認できます。PC1にはpetal_length(0.581)とpetal_width(0.566)が強く寄与しており、PC2にはsepal_width(0.926)が特に強く寄与しています。
まとめ
今回はDataikuの統計タブを使ってIrisデータセットでPCAを実行しました。 PC1とPC2の2つだけで全体の約96%の情報を説明できることがわかり、4次元のデータを2次元に削減しても情報がほぼ失われないことが確認できました。 また、Dataikuの統計タブでのPCAは可視化のみであり、実際に次元を落としたデータを生成するにはPythonレシピなどで行う必要があることに注意が必要です。





