初学者向けにAIがデータをグループ分けする仕組みをやさしく解説

AIの「クラスタリング」をご存知ですか?これは、データの中から「似たもの同士」を自動でグループ分けする「教師なし学習」技術です。この記事では、その基本的な仕組み、顧客分析などの活用例、そして評価の難しさといった注意点まで、初心者にもわかりやすく解説します。
目次
導入 気づかないうちに、あなたも「グループ分け」されているかも?
ECサイトで買い物をした後に、「あなたへのおすすめ」として興味のある商品が表示された経験はありませんか?実はその裏側で、AIがあなたの購買パターンを分析し、「節約志向グループ」や「高級志向グループ」といった集団に自動で分類しているのかもしれません。
このように、データの中から隠れたパターンを見つけ出し、自動でグループ分けを行う技術が「クラスタリング」です。クラスタリングは、マーケティングから医療まで、様々な分野で活用される便利な技術です。
この記事を読めば、AIがどのようにしてデータをグループ分けするのか、その基本的な考え方から具体的な使い方、そして注意点まで、初心者の方にもわかりやすく理解できます。データ分析の面白い世界へ、一緒に一歩踏み出してみましょう。
クラスタリングの基本の考え方:「似たもの同士」を集める技術
クラスタリングの基本的な考え方は非常にシンプルです。それは、「似たデータは同じグループに、異なるデータは別のグループに分ける」という原則に基づいています。
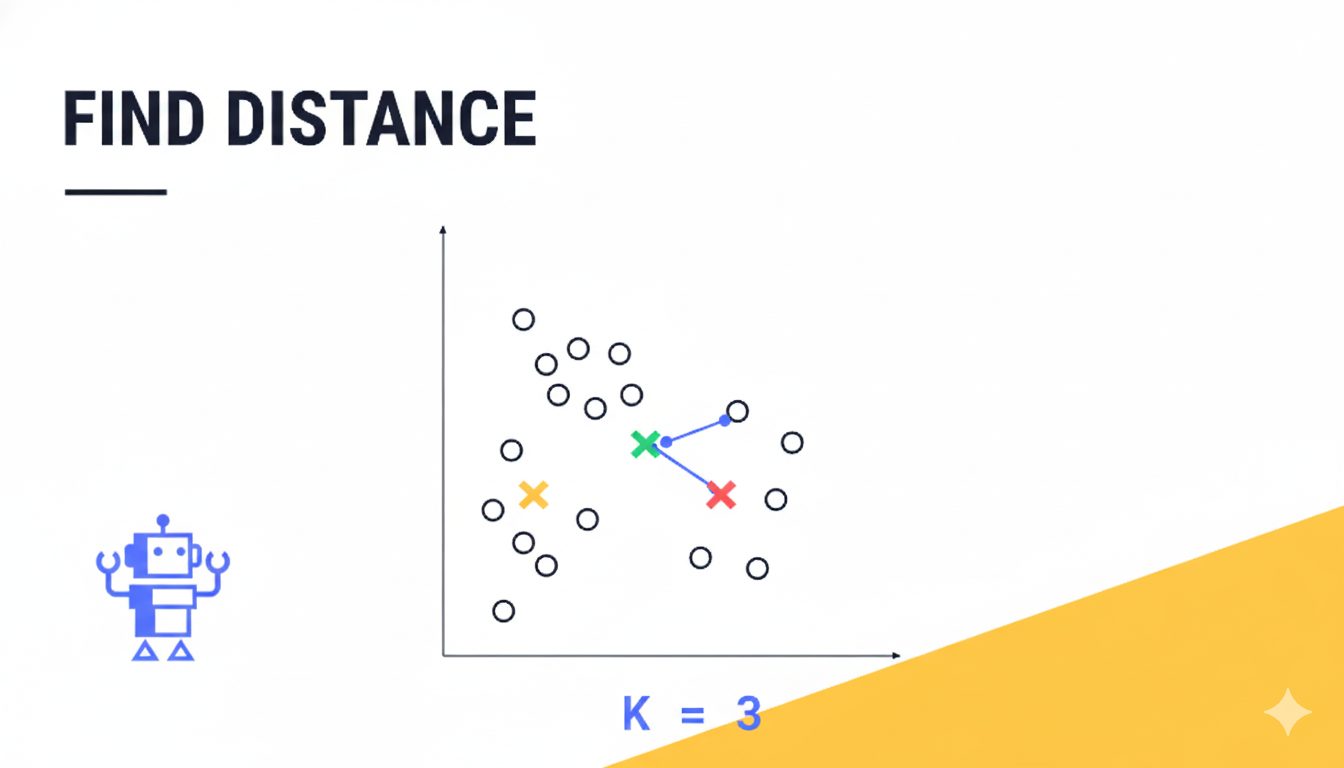
AIは、データ同士がどれくらい似ているかを「距離」という指標で測ります。物理的な距離と同じように、データの特徴が近いほど「距離が近く」、特徴が遠いほど「距離が遠い」と判断します。
例えば、「モール顧客データ」に含まれる「年間収入」と「支出スコア(お金の使いやすさを示す指標)」という2つのデータを使って、顧客を散布図にプロットしたとします。
この図を見ると、データがいくつかの自然な「かたまり」を作っているように見えませんか?クラスタリングとは、まさにこの「かたまり」、つまり「クラスタ」を見つけ出す技術です。
- 同一クラスタ内のデータは、互いに距離が近く(性質が似ている)
- 異なるクラスタ間のデータは、互いに距離が遠い(性質が似ていない)
AIは、このようなデータ間の距離を基準に、自動でグループを形成していきます。
クラスタリングの仕組み:なぜ「正解」がなくても大丈夫なの?
 クラスタリングの大きな特徴は、「教師なし学習(Unsupervised Learning)」というAIの学習方法の一種である点です。これには「正解」となるラベルがなくても、AIが自らデータ内の構造を見つけ出すことができます。
クラスタリングの大きな特徴は、「教師なし学習(Unsupervised Learning)」というAIの学習方法の一種である点です。これには「正解」となるラベルがなくても、AIが自らデータ内の構造を見つけ出すことができます。
「教師あり学習」との違いを見てみましょう。
- 教師あり学習: 正解(ラベル)が付けられたデータ(例:「このメールはスパム」「この画像は猫」)を使って、明確な答えを予測するモデルを学習させます。
- 教師なし学習: 正解(ラベル)がないデータの中から、AIがデータに隠されたパターンや構造(グループ)を自ら発見します。
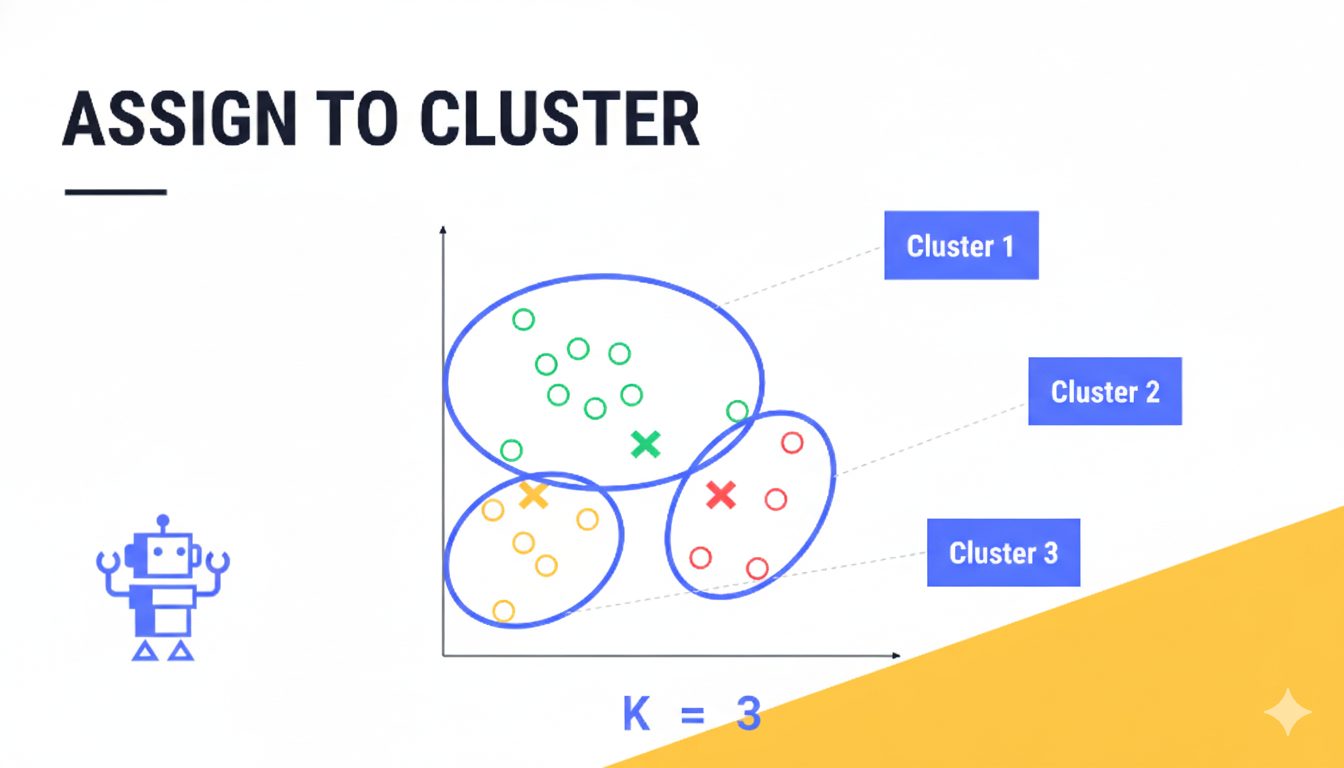
では、どうやってAIは正解なしにグループ分けをするのでしょうか?代表的なアルゴリズムである「k-means法」(これは中心ベースの手法と呼ばれ、他にも階層的クラスタリングや密度ベースのDBSCANといった様々なアルゴリズムが存在します)の簡単な仕組みを見てみましょう。
- 最初に「k個」(例えば3個)のグループの中心点を、データ空間にランダムに配置します。
- 各データは、自分から一番近い中心点のグループに所属します。
- 各グループに所属するデータの平均的な位置(重心)に、中心点を移動させます。
- 中心点の位置がほとんど動かなくなるまで、ステップ2と3を繰り返します。
このように、k-means法は簡単なステップを繰り返すだけで、データが自然に形成するかたまり(クラスタ)を見つけ出すことができるのです。
実際の使い方:データから顧客グループを発見してみよう
クラスタリングは、ビジネスの現場でどのように役立つのでしょうか。「モール顧客データ」を例に、具体的な活用イメージを見てみましょう。このデータには、「年齢」「年間収入」「支出スコア」といった顧客の情報が含まれています。
特に「年間収入」と「支出スコア」の2つのデータを使って散布図を作り、クラスタリングを行うと、顧客の消費行動パターンを視覚的に捉えることができます。例えば、以下のような顧客グループが発見できるかもしれません。
- グループA: 収入は高いが支出は少ないグループ(節約傾向)
- グループB: 収入も支出も高い(優良顧客グループ)
- グループC: 収入は平均的だが、支出も平均的(標準顧客グループ)
- グループD: 収入は低いが支出は多いグループ(浪費傾向)
- グループE: 収入は低いが、支出も少ない(節約志向グループ)
これらのグループ名は、AIが自動で分けたデータのかたまりに、私たちがビジネスの知識(ドメイン知識)を使って意味付けをしたものです。AIは「グループE」としか教えてくれませんが、それが「収入も支出も少ない顧客層」だと解釈するのは人間の役割です。
このように顧客をグループ分け(セグメンテーション)することで、それぞれのグループの特性に合わせた効果的なマーケティング戦略を立てることが可能になります。例えば、「グループB(優良顧客)」には限定の特別オファーを送り、「グループD(浪費傾向)」には分割払いやポイントキャンペーンを案内するといった施策が考えられます。
よくある誤解と注意点:「最高のグループ分け」は存在するの?
クラスタリングは非常に強力なツールですが、一つ、本質的で大きな注意点があります。それは、結果の客観的な評価が極めて難しいということです。
「教師なし学習のモデルの性能はどうやって評価すればよいのか?」という問いに対する正確な答えは、驚くかもしれませんが「できない」です。
- 教師あり学習の場合: 「正解データ」が存在するため、「正解率95%」のようにモデルの性能を客観的な数値で評価できます。
- 教師なし学習の場合: そもそも「正解」がないため、どのグループ分けが「最も正しい」かを判断する明確な基準が存在しないのです。
ここで最も重要なのは、「教師なし学習では優秀なモデルを作れないことが問題なのではなく、作ったとしてもそれを選ぶことができないことが問題なのです」という点です。
この問題を理解するために、面白い例え話をしましょう。 「次の1回のジャンケンで勝つモデルを作る」という課題があったとします。あなたは「グーを出すモデル」「チョキを出すモデル」「パーを出すモデル」の3つを作りました。ここで相手が出す手(=正解ラベル)をこっそり見て、「パー」だと知ったとします。そして、あなたは自信満々に「チョキを出すモデル」を選び、「見事に教師なし学習で勝利モデルを選べました!」と報告します。
これはおかしいですよね?もし正解ラベル(相手の手)を知らなければ、3つのモデルから1つを選ぶことはできませんでした。これと同じように、正解ラベルのないデータでクラスタリングを行った後、性能評価のために用意したラベル付きデータを使って「最も良い結果だったモデル」を選ぶのは、後から答えを見てモデルを選んでいるのと同じで、致命的な間違いなのです。
結論として、クラスタリングの結果をどう解釈し、活用するかは、最終的に分析者の目的とドメイン知識(その分野の専門知識)に委ねられます。AIが自動で見つけ出したグループ分けがビジネス上どのような意味を持つのかを解釈し、意思決定に繋げるのは、人間の重要な役割なのです。
まとめ クラスタリングを学んだら、次は何を学ぶ?
この記事では、クラスタリングの基本について解説しました。最後に要点をまとめておきましょう。
- クラスタリングは、正解ラベルのないデータから「似たもの同士」のグループを自動で見つけ出す「教師なし学習」の手法です。
- 顧客のグループ分け(セグメンテーション)に応用することで、各グループに特化したマーケティング戦略の立案などに役立ちます。
- 教師あり学習とは異なり、結果に明確な「正解」がなく、どのモデルが最適かを客観的に評価することが難しい点に注意が必要です。
クラスタリングの面白さに触れたあなたが次に学ぶべきステップとして、同じ「教師なし学習」の仲間である以下の手法をおすすめします。
- 次元削減: 多数の特徴量を持つ高次元のデータを、重要な情報を保ったまま2次元や3次元に圧縮して可視化しやすくする技術です。画像の圧縮やノイズ除去にも使われます。
- アソシエーション分析: 「商品Aを買う人は、商品Bも一緒に買う傾向がある」といった、データ間の関連性を見つけ出す技術です。ECサイトのレコメンド機能などに応用されています。
- 異常検知: クレジットカードの不正利用検知のように、大多数のデータから逸脱した「いつもと違う」パターンを見つけ出す技術です。
クラスタリングは、データに隠された物語を読み解くための強力な第一歩です。
おまけ
分析力のみ0.1伸ばしました。この知識を実践で活用し、実装力も磨いていきたいと思います!