Pythonで実践する重回帰分析入門:AI初心者向け解説
重回帰分析は、複数の説明変数を用いて目的変数を予測する手法です。本記事では、重回帰分析のアルゴリズムとPythonを用いたモデル実装のチュートリアルを、初心者でも理解しやすいように解説します。
目次
重回帰分析とは
重回帰分析は、単回帰分析の拡張版として、より複雑な関係性をモデル化することができます。
重回帰分析のアルゴリズムを具体的な例で説明します。例えば、あるコンビニの傘の来週の売り上げを予測したいとします。この場合、来週の売り上げが目的変数になります。そして、売り上げに影響を与えると思われる複数の要因が説明変数になります。具体的には、天気、曜日、イベントの有無、広告費などが考えられます。
ただ、各説明変数が目的変数に与える影響の大きさは異なります。今回の場合だと、コンビニの傘の売り上げは曜日や広告費などの影響は少なく、逆に天気の影響を強く受けることが想定されます。このように、各説明変数がどの程度目的変数に影響を与えるのかを示す指標が回帰係数と呼ばれます。重回帰分析ではこの回帰係数を求めるパラメータ推定を行います。

プログラム解説〜データ前処理〜
今回はこちらのKaggleのKickstarter Projectsのデータを例に実践していきます。KaggleのKickstarter Projectsは、クラウドファンディングサイト「Kickstarter」で行われたプロジェクトのデータセットです。データセットには、プロジェクト名、カテゴリー、開始日、終了日、目標金額、資金調達額、支援者の数、プロジェクト状況など、さまざまな情報が含まれています。
Kickstarter Projects
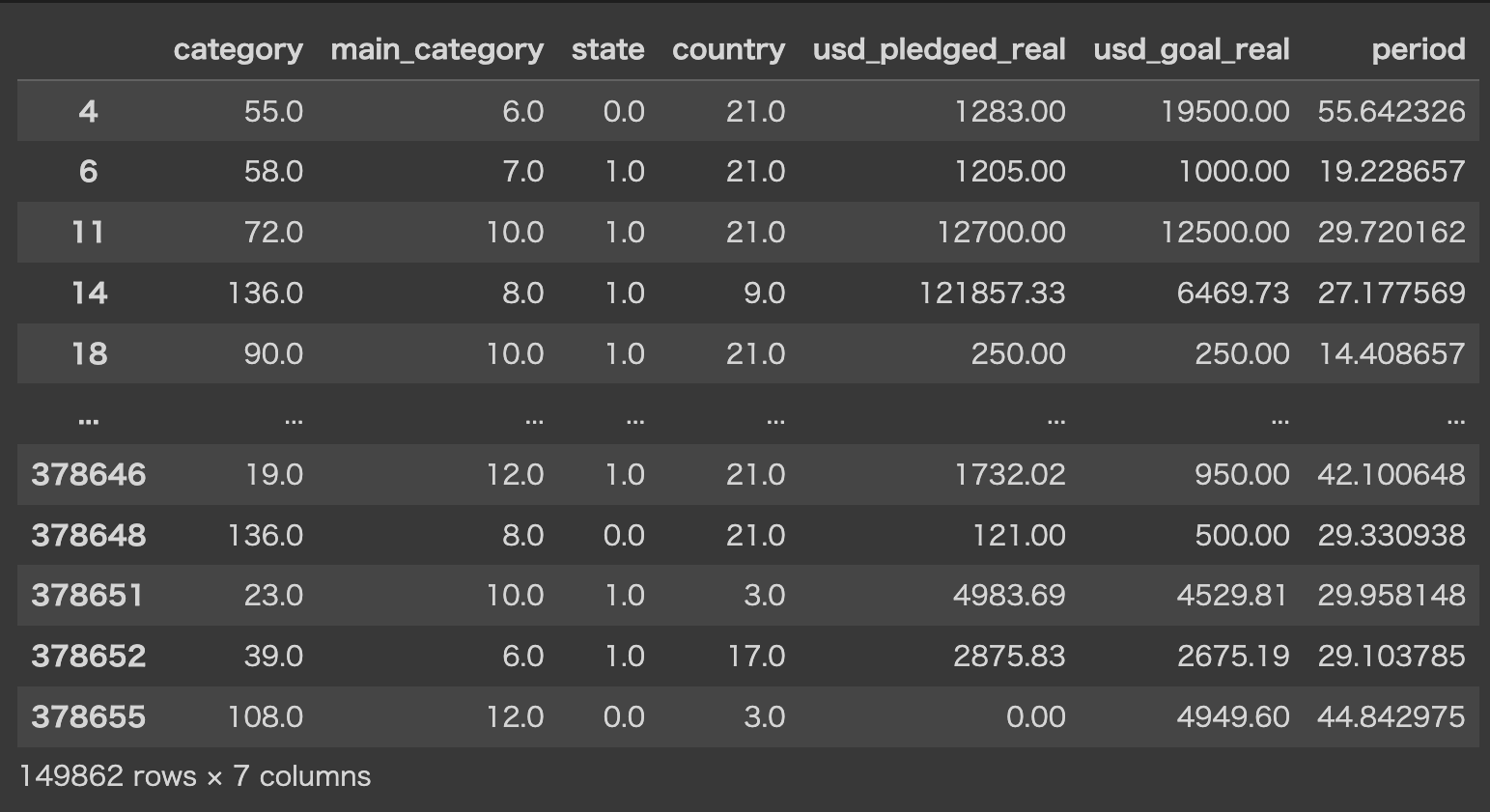
データ前処理を済ませたデータがこちらになります。
プログラム解説 〜データの標準化と分割処理〜
まず、下記のコードを実行し、説明変数の標準化とデータの分割処理を行います。

プログラム解説 〜モデルの学習〜
次に下記コードを実行しモデルの初期化と学習を行います。これで重回帰モデルの実装は完成です。

プログラム解説 〜構築したモデルのパラメータの値〜
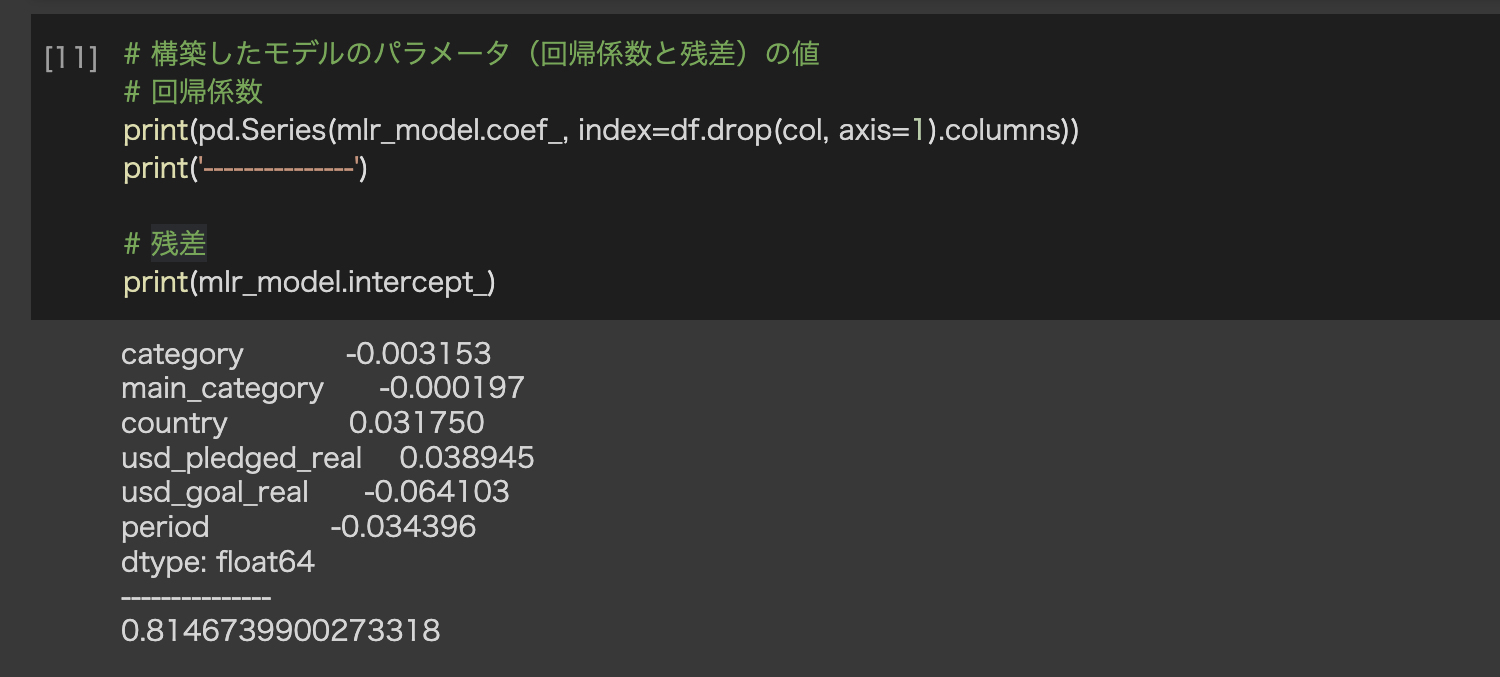
先ほど構築した重回帰モデルの回帰係数と残差の値を確認してみましょう。残差とは、実際の目的変数と予測された目的変数との差をさし、残差が小さいほど予測モデルの精度が高いと言えます。また、残差は、正規分布に従うことが望ましいとされています。正規分布に従っている場合、残差の平均値が0に近くなります。残差が正規分布に従っていない場合、モデルに改善の余地がある可能性があります。
プログラム解説 〜構築したモデルの決定係数〜
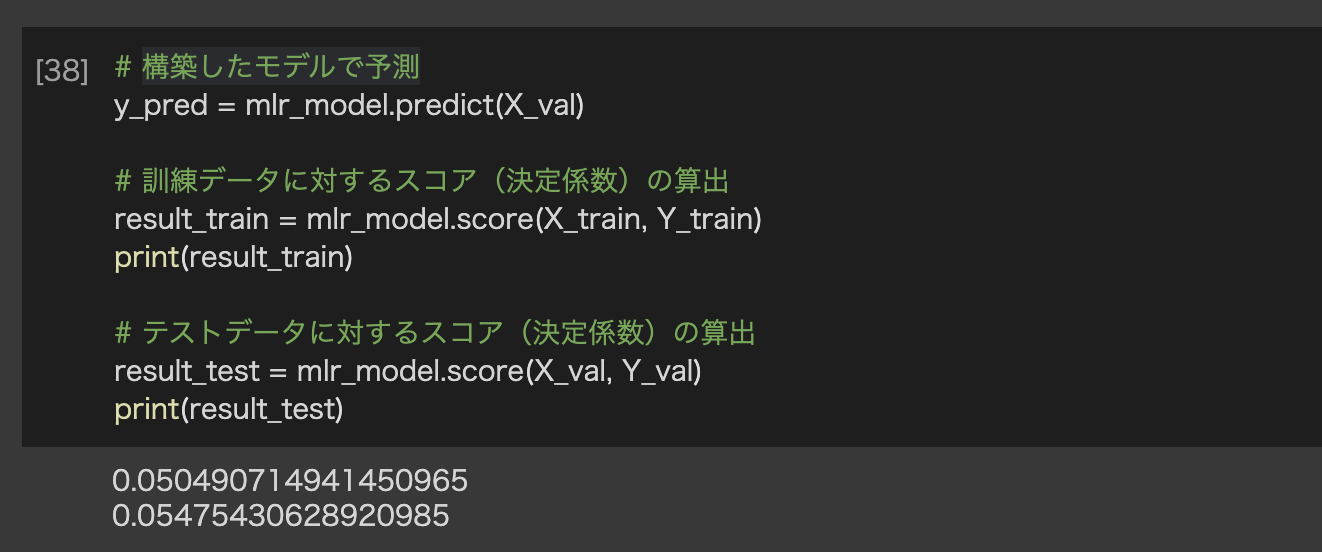
最後に、構築したモデルの決定係数を算出していきます。
決定係数は、重回帰分析における予測モデルの当てはまりの良さを評価する指標の一つです。決定係数は、実測値と予測値の間の分散の比率を表し、0から1の値を取ります。0に近いほど予測モデルが当てはまりが悪く、1に近いほど予測モデルが当てはまりが良いと言えます。
しかし、決定係数は予測のあてはまりの良さを示すため、予測する内容や分析目的によっては決定係数が高くても意味をなさない場合があるのが注意点です。
プログラムの全容
今回、実装したプログラムは下記リンクから詳細を確認することができます。是非ご活用ください。
Google Colaboratory

