DatabricksとDataikuをどう選ぶ?違いと併用戦略を徹底解説
本記事では、データ分析・AI活用の現場で注目されている2大プラットフォーム、DatabricksとDataikuについて、機能や特徴、導入の適性を比較・整理し、実践的な「使い分け」戦略を解説します。
1 イントロダクション
近年、「データをどう活かすか」が企業の競争力を左右する重要な要素となっています。
その流れの中で注目されているのが、データ活用のプロセス全体を支援する統合プラットフォームです。中でも、DatabricksとDataikuという2つのツールは、多くの企業が採用を検討する有力な選択肢となっています。
この2つは一見似ているようでいて、対象ユーザーや操作スタイル、導入のスコープが大きく異なります。
本記事では、DatabricksとDataikuの違いや使い分けのポイントを整理し、自社のユースケースに合った選定や使い分けのヒントを提供していきます。
2 詳細説明
2.1 技術の基本原理(アーキテクチャの違い)
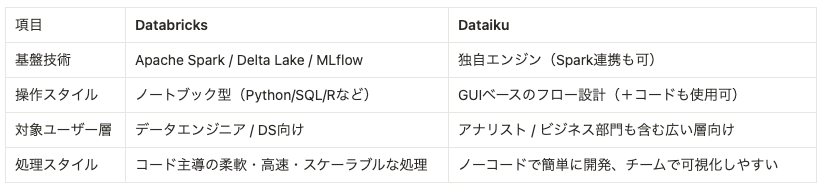
2.2 それぞれの強み
- Databricksの特徴
- 大規模データの高速処理に強い
- MLflow、Unity Catalog など、ML/MLOpsへの完全対応
- クラウドスケーラブルな分析基盤
- Dataikuの特徴
- ノーコード/ローコードで簡単に分析フローを構築
- ビジネス部門を含むチームでの協働が容易
- AutoMLや可視化機能が充実
3 使用例
3.1 具体的な適用例
Databricks:
製造業でのIoTデータのリアルタイム処理
デモ記事では、風力発電所などのIoTセンサーデータをリアルタイムに取り込み、Databricks Lakehouseで予知保全ソリューションを構築する流れを紹介しています。Databricks公式デモ
生成AIやLLMトレーニングの大規模基盤
DollyやDBRXといったオープンソースLLMのトレーニングを含む、LLM活用のためのスケーラブルな環境が提供されていることが公式ブログで説明されています。Databricksブログ – DBRX紹介
Dataiku:
小売業でのストアセグメンテーション
Store Segmentation Solution は、店舗を購買傾向や地理特性でグループ分けして、マーケティング戦略や商品配分を最適化します。Store Segmentation Solution
マーケティング部門によるA/Bテスト分析
DataikuのA/Bテスト機能や専用プラグイン(AB test calculator)を使って、メール開封時間の変更などマーケ施策の効果をGUI上で分析できます。Dataikuナレッジベース – A/Bテスト
3.2 成功事例とその影響
Abacus Medicine事例(Databricks + Monte Carlo)
- EU圏で医薬品データ処理を担うAbacus Medicineが、DatabricksをML基盤として採用し、Monte Carloと組み合わせて高信頼性のデータ運用を実現しています。Abacus事例 – Databricks公式ブログ
DatabricksとDataikuの使い分け戦略:EGA(Emirates Global Aluminium)
- EGAでは、製造現場や営業・物流部署など非エンジニアの現場ユーザーがDataiku上で分析プロトタイプを作成し、Databricksで本番スケーラブル運用を実現しています。EGA導入事例 – Dataiku公式
4 利点と課題
4.1 メリット
Databricks
柔軟性・処理性能が高く、構成の自由度も高い
MLOpsのワークフロー全体(トレーニング、展開、モニタリング)を統合でき、高速でスケーラブルに実行可能。Databricks MLOps解説
AIやMLOpsに強く、スケーラビリティも優れる
Databricksはマルチクラウド対応&自動クラスタ設定で、大規模・複雑なMLパイプラインにも対応可能。Hatchworks – Databricks MLOps紹介
Dataiku
ノーコードで多職種連携がしやすい
コーディング不要なビジュアルレシピやGit連携により、ビジネス部門も含む多様なユーザーが協業可能。
分析プロセスを可視化で共有でき、教育効果も高い
フロー図・Wiki・ディスカッション機能・モデルドリフト検知などにより、業務の透明性と教育効果を両立。Dataikuブログ – Modern Analytics
4.2 課題と克服方法
- Databricks
- 課題:非エンジニアには学習コストが高い
- 克服のポイント:GUIツールとの併用(例:Dataiku経由)で利用ハードルを下げる
- Dataiku
- 課題:大規模処理や高負荷環境では性能に限界あり
- 克服のポイント:Databricksクラスタへの処理プッシュダウン実行で補完可能
5 将来展望
5.1 今後の発展可能性
Databricks
Unity Catalog によるガバナンス強化
Unity Catalog は、データ・AIアセット全体にわたる統合ガバナンス(行レベル・列レベル制御、監査、リネージなど)を提供し、マルチクラウド/オープン形式対応でも注目されています。Unity Catalog – Databricks
LLM・生成AIへの対応拡大
Databricksは、MosaicML買収後のLakehouse上でLLMトレーニングやAIエージェント開発を進めており、大規模AIワークロードの本番運用基盤としての地位を強めています。Databricks – Wikipedia
Dataiku
生成AI統合とノーコード民主化
Dataikuは「LLM Mesh」やAIエージェント統合、自動生成コード補助などにより、非エンジニアでも生成AIを活用できるような機能強化を進行中です。Dataikuブログ – Generative AI
業務自動化基盤としての成熟
生産性向上のためのAIによるワークフロー自動化や責任あるAIガバナンス機能にも力を入れており、大規模業務へのAI導入の実運用化に貢献しています。
5.2 他技術との相互作用
Databricks Connect v2
VSCodeやJupyter、Airflow、そしてDataikuなど様々なツールからDatabricksクラスターに直接接続できるようになり、開発/実行のハイブリッド体験が向上しています。Databricksブログ – Connect v2、Dataikuブログ – Databricks連携
これにより、「PoCはDataiku、本番処理はDatabricks」という併用戦略が技術的に実現可能・推奨される運用パターンとなりました。
マルチ/ハイブリッドクラウドの展開
両者ともAWS・Azure・GCPなどの主要クラウドに対応し、LakehouseやAI活用の拡張性を活かした柔軟なインフラ展開が進んでいます。
6 まとめ
6. まとめ
DatabricksとDataikuは、いずれもデータ活用を加速させる強力なプラットフォームですが、その設計思想と適用領域には明確な違いがあります。
Databricksは、大規模で複雑なデータ処理やMLOps、生成AIのような高度なユースケースに強く、クラウドネイティブかつ柔軟性の高い基盤を提供します。一方、Dataikuはノーコード/ローコード環境を活かし、ビジネスユーザーやアナリストを巻き込んだPoCや分析フローの設計に適しています。
特に注目すべきは、「PoCや前処理はDataiku、本番処理はDatabricks」という併用戦略です。これは両者の強みを活かしながら、組織全体でのデータ活用と本番環境でのスケーラブルな実行の両立を可能にします。
使い分けの指針
- 非エンジニア主体のPoC・分析設計:Dataiku
- 大量データの本番運用・MLOps:Databricks
- GUIでの迅速な仮説検証:Dataiku
- 本格的なAI活用やガバナンス制御:Databricks
今後のデータ戦略では、「どちらか一方を選ぶ」のではなく、「どのように連携・補完して活用するか」が成功の鍵になります。DatabricksとDataikuの併用は、その現実的かつ再現性のある解のひとつです。

