Claudeとdatabricks LLMのgenieと接続する方法してみました。
【databricks】Claude MCPをdatabricksで使ってみた2: Claudeとdatabricks LLMのgenieと接続する方法
1. 初めに
MCPとdatabricksの説明については前回のブログをご参照ください。
今回はdatabricksに内蔵されているAI「Genie」とClaude desktopをMCPで接続してみました。接続のイメージは以下の通りです。

Unity Catalogとの直接接続とは異なり、ClaudeからのリクエストをGenieが処理する仕組みとなっています。そのため、直接接続ほどClaudeの推論能力を活かすことはできません。一方で、GenieがUnity Catalogからのデータ取得を最適化してくれるため、大量のデータがある場合でも必要なデータのみを効率的に取得できるというメリットがあります。
今回はこの記事をメインに参考にしています。
https://qiita.com/taka_yayoi/items/b29edb7daa50057d9e36
2. 環境設定
必要なもの
- Claude desktop(アカウント)
- databricks API (設定の方法は前記事参照), genie space ID (事前にgenie UI にいって部屋を建ててください。), databricks host ID
databricks host IDとgenie space IDはURLの下記の部分に該当します。
databricks host ID genie space ID
┌────────────────────────────────┐ ┌─────────┐
https://xxxxx.cloud.databricks.com/genie/rooms/xxxxxxxxxxx?o=xxxxxxxx
3. 構築手順
1.Local Host MCP Serverを設定する
local 環境にフォルダを作ります。名前はなんでもいいです。下図はフォルダディレクトリのイメージです。
my-genie-mcp/
├ main.py
├ dbapi.py
├ databricks_formatter.py
├ pyproject.tomlmain.py
"""
Databricks Genie MCP Server
MCPを使用してGenieとの対話を可能にするサーバー
"""
from mcp.server.fastmcp import FastMCP
from dbapi import genie_conversation
from databricks_formatter import format_query_results
# MCPサーバーを初期化
# サーバー名を指定して新しいインスタンスを作成
mcp = FastMCP("Databricks Genie MCP Server")
@mcp.tool()
async def start_conversation(content: str) -> str:
"""
Genie APIとの会話を開始する
Args:
content (str): Genieに送信するメッセージ内容
Returns:
str: Genieからのレスポンスを整形した結果
"""
try:
# Genie APIを呼び出して応答を取得
result = await genie_conversation(content)
# 応答結果を見やすい形式に整形
return format_query_results(result)
except Exception as e:
# エラーが発生した場合はエラーメッセージを返す
return result
# メインエントリーポイント
if __name__ == "__main__":
# デフォルトでstdioトランスポートを使用してサーバーを起動
# これによりコマンドラインからの対話が可能になる
mcp.run()dbapi.py
"""
Databricks API通信モジュール
Genieとの対話に必要なAPI呼び出しを管理します
"""
from typing import Any, Dict, Optional
import os
import asyncio
import httpx
from dotenv import load_dotenv
# 環境変数を.envファイルから読み込み
load_dotenv()
# Databricks接続に必要な設定値
DATABRICKS_HOST = os.environ.get("DATABRICKS_HOST", "<your databricks host>")
DATABRICKS_TOKEN = os.environ.get("DATABRICKS_TOKEN", "<your databricks token>")
DATABRICKS_GENIE_SPACE_ID = os.environ.get("DATABRICKS_GENIE_SPACE_ID", "<your genie space ID>")
# APIエンドポイントの定義
GENIE_START_CONVERSATION_API = "/api/2.0/genie/spaces/{space_id}/start-conversation" # 会話開始用エンドポイント
GENIE_GET_MESSAGE_API = "/api/2.0/genie/spaces/{space_id}/conversations/{conversation_id}/messages/{message_id}" # メッセージ取得用エンドポイント
STATEMENT_API = "/api/2.0/sql/statements/{statement_id}" # SQLステートメント実行結果取得用エンドポイント
async def make_databricks_request(
method: str,
endpoint: str,
json_data: Optional[Dict[str, Any]] = None,
params: Optional[Dict[str, Any]] = None
) -> Dict[str, Any]:
"""
DatabricksのAPIにリクエストを送信する汎用関数
Args:
method (str): HTTPメソッド('get'または'post')
endpoint (str): APIエンドポイントのパス
json_data (Optional[Dict[str, Any]]): POSTリクエスト用のJSONデータ
params (Optional[Dict[str, Any]]): GETリクエスト用のクエリパラメータ
Returns:
Dict[str, Any]: APIレスポンスのJSONデータ
"""
url = f"{DATABRICKS_HOST}{endpoint}"
# 認証ヘッダーの設定
headers = {
"Authorization": f"Bearer {DATABRICKS_TOKEN}",
}
async with httpx.AsyncClient() as client:
try:
# HTTPメソッドに応じてリクエストを実行
if method.lower() == "get":
response = await client.get(url, headers=headers, params=params, timeout=30.0)
elif method.lower() == "post":
response = await client.post(url, headers=headers, json=json_data, timeout=30.0)
else:
raise ValueError(f"サポートされていないHTTPメソッド: {method}")
response.raise_for_status()
return response.json()
except httpx.HTTPStatusError as e:
# HTTPエラーの詳細情報を取得して例外を発生
error_message = f"HTTPエラー: {e.response.status_code}"
try:
error_detail = e.response.json()
error_message += f" - {error_detail.get('message', '')}"
except Exception:
pass
raise Exception(error_message)
except Exception as e:
raise Exception(f"Databricks APIリクエスト中にエラーが発生: {str(e)}")
async def genie_conversation(content: str, space_id: Optional[str] = None) -> Dict[str, Any]:
"""
Genieとの会話を実行し、結果が得られるまで待機する
Args:
content (str): Genieに送信するメッセージ内容
space_id (Optional[str]): Genie Space ID(未指定時は環境変数から取得)
Returns:
Dict[str, Any]: 会話の実行結果
"""
if not space_id:
space_id = DATABRICKS_GENIE_SPACE_ID
if not space_id:
raise ValueError("Genie Space IDが必要です。環境変数DATABRICKS_GENIE_SPACE_IDを設定するか、パラメータとして指定してください。")
# 会話開始リクエストの作成
statement_data = {
"content": content
}
# 会話を開始し、conversation_idとmessage_idを取得
endpoint_url = GENIE_START_CONVERSATION_API.format(space_id=space_id)
response = await make_databricks_request("post", endpoint_url, json_data=statement_data)
message = response.get("message")
conversation_id = message["conversation_id"]
message_id = message["id"]
if not conversation_id:
raise Exception("レスポンスからconversation_IDの取得に失敗しました")
# 会話生成完了をポーリング
max_retries = 60 # 最大リトライ回数(10秒間隔で10分)
retry_count = 0
while retry_count < max_retries:
# メッセージのステータスを確認
message_status = await make_databricks_request(
"get",
GENIE_GET_MESSAGE_API.format(space_id=space_id, conversation_id=conversation_id, message_id=message_id)
)
status = message_status["status"]
if status == "COMPLETED":
# 完了した場合、クエリ結果を取得
query_result_statement_id = message_status["attachments"][0]["query"]["statement_id"]
statement_status = await make_databricks_request(
"get",
STATEMENT_API.format(statement_id=query_result_statement_id)
)
return statement_status
elif status in ["FAILED", "CANCELED"]:
error_message = message_status["status"]
raise Exception(f"メッセージの取得に失敗: {error_message}")
# 次のポーリングまで待機
retry_count += 1
return message["content"]databricks_formatter.py
from typing import Any, Dict
def format_query_results(result: Dict[str, Any]) -> str:
"""Format query results into a readable string."""
# Check if result is empty or doesn't have the expected structure
if not result or 'manifest' not in result or 'result' not in result:
return "No results or invalid result format."
# Extract column names from the manifest
column_names = []
if 'manifest' in result and 'schema' in result['manifest'] and 'columns' in result['manifest']['schema']:
columns = result['manifest']['schema']['columns']
column_names = [col['name'] for col in columns] if columns else []
# If no column names were found, return early
if not column_names:
return "No columns found in the result."
# Extract rows from the result
rows = []
if 'result' in result and 'data_array' in result['result']:
rows = result['result']['data_array']
# If no rows were found, return just the column headers
if not rows:
# Format as a table
output = []
# Add header
output.append(" | ".join(column_names))
output.append("-" * (sum(len(name) + 3 for name in column_names) - 1))
output.append("No data rows found.")
return "\n".join(output)
# Format as a table
output = []
# Add header
output.append(" | ".join(column_names))
output.append("-" * (sum(len(name) + 3 for name in column_names) - 1))
# Add rows
for row in rows:
row_values = []
for value in row:
if value is None:
row_values.append("NULL")
else:
row_values.append(str(value))
output.append(" | ".join(row_values))
return "\n".join(output)pyproject.toml
[project]
name = "databricks_test"
version = "0.1.0"
description = "Databricks Genie Integration"
requires-python = ">=3.10"
dependencies = [
"httpx>=0.28.1",
"mcp[cli]>=1.3.0",
]2. claude_desktop_config.jsonに先ほどのファイルのディレクトリを入れる
claude desktop開発者用の設定から構成を編集を押すと、claude_desktop_config.jsonに誘導されます。
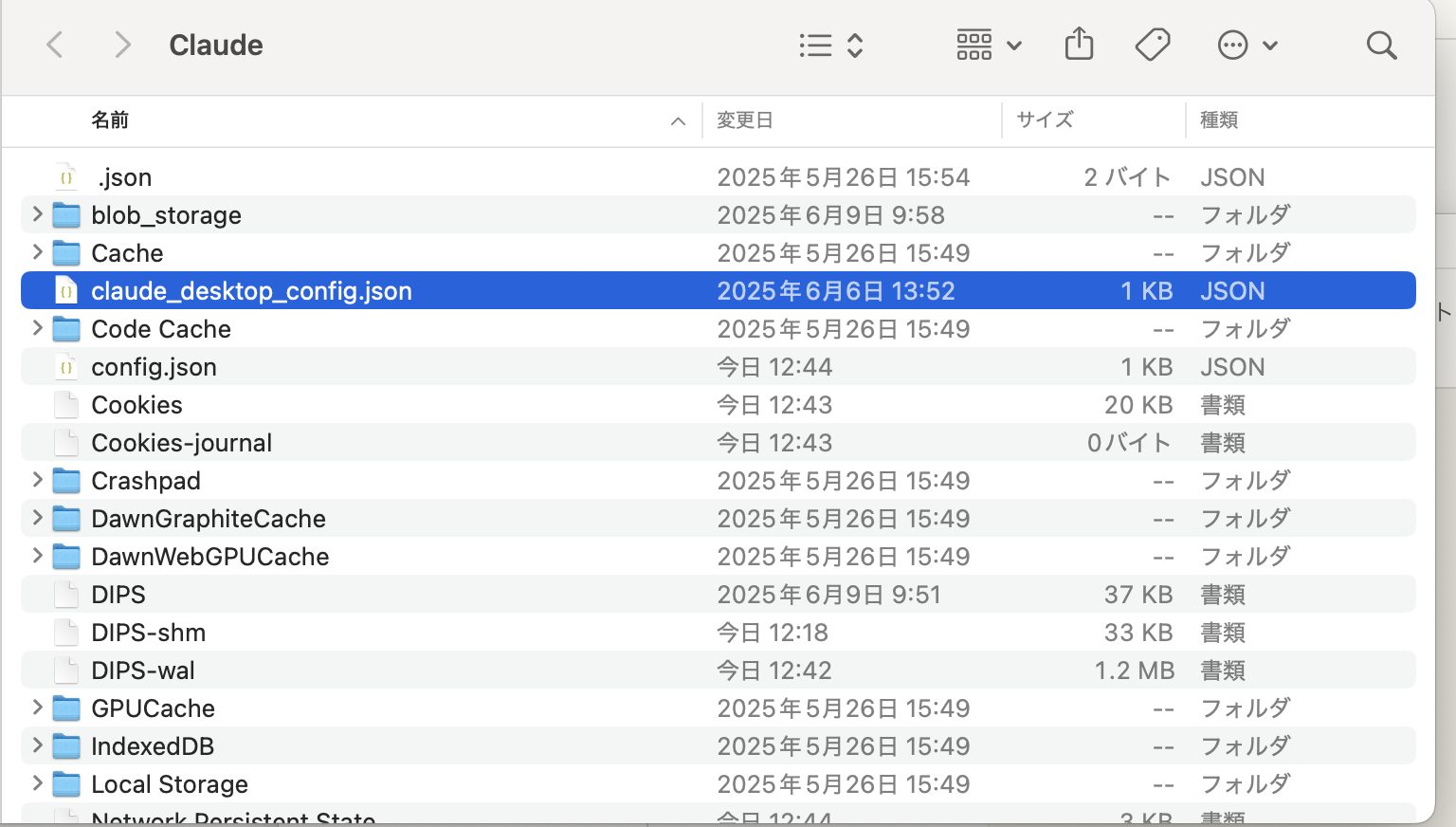
この中に次のコードを入れてください。
{
"mcpServers": {
"databricks_genie_test": {
"command": "uv",
"args": [
"--directory",
"<your directory to file>/my-genie-mcp",
"run",
"main.py"
],
"env": {
"DATABRICKS_HOST": "<your databricks host>",
"DATABRICKS_TOKEN": "<your databricks token>",
"DATABRICKS_GENIE_SPACE_ID": "<your genie space ID>"
}
}
}
}これで設定完了です!claude desktopを再起動し、再度開発者用の設定を開くと、以下のようなdatabricks_genieのmcpが見れるはずです。
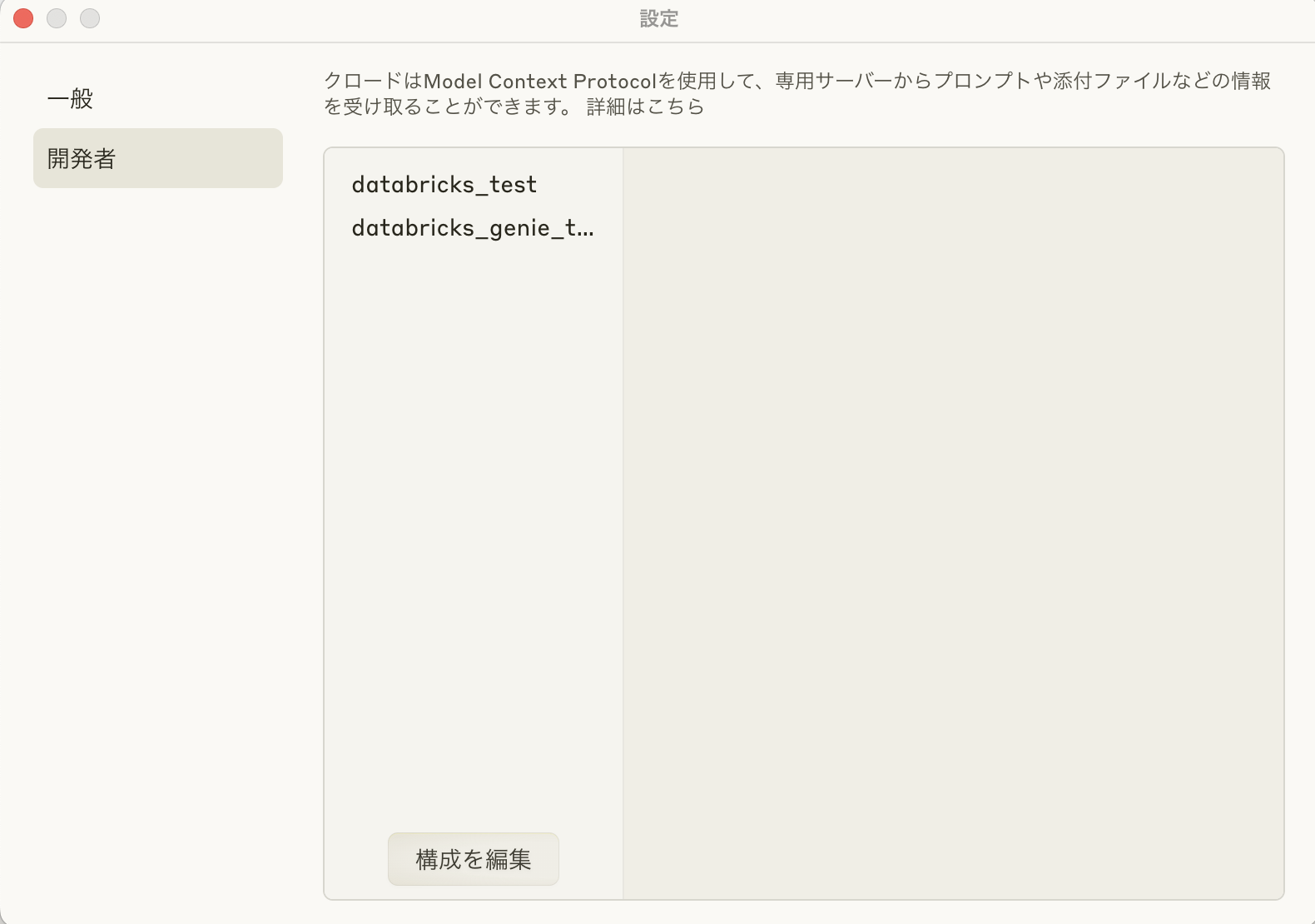
2段目のmcpが今回設定したもの。1段目の設定については前回のブログ参照
4. 実際に使ってみた
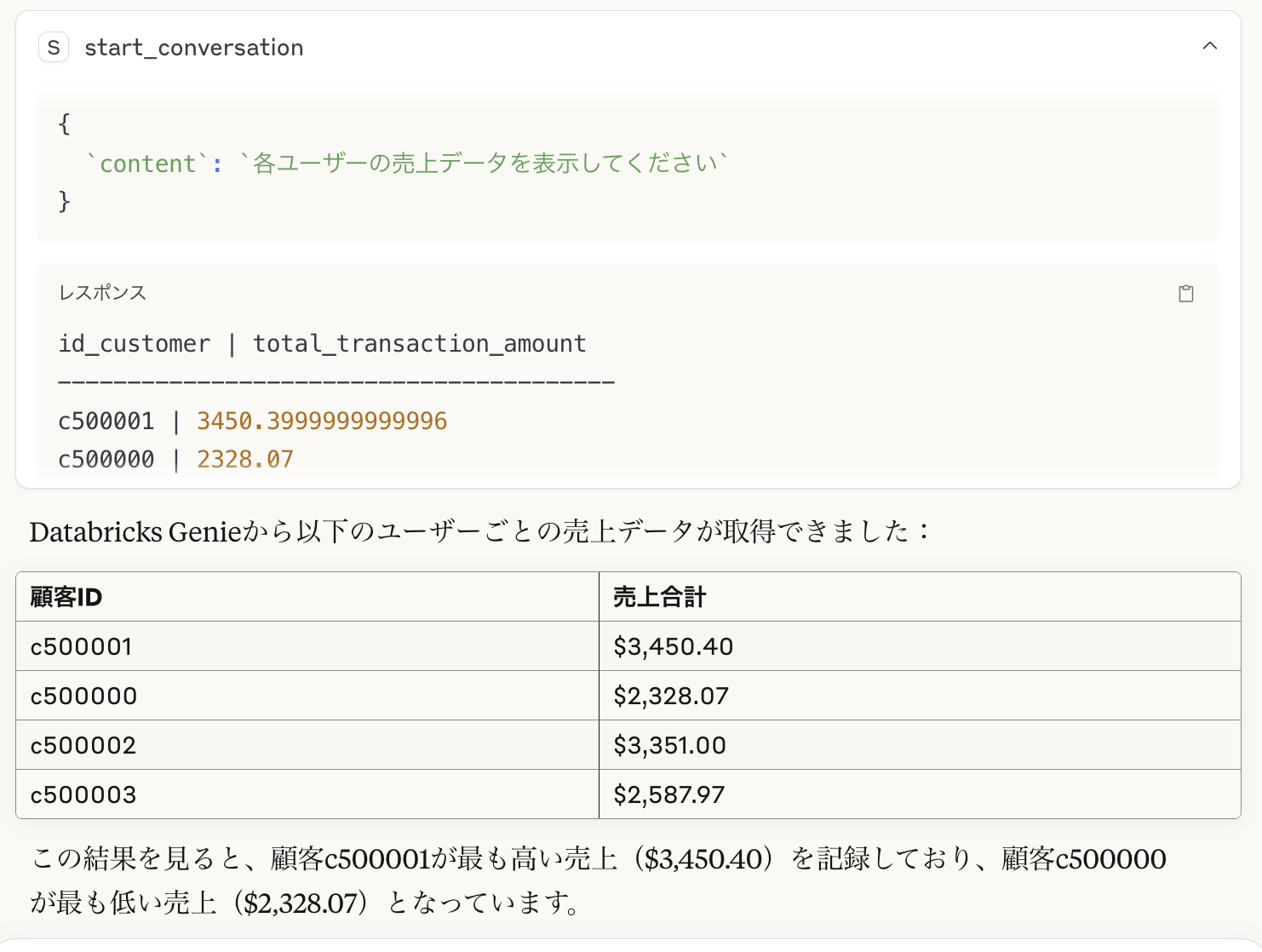
databricks genieにユーザーごとの売上を聞いて。という質問をしてみました!
claude がgenieに自然言語で質問していますね。レスポンスのデータはしっかり取得できています。
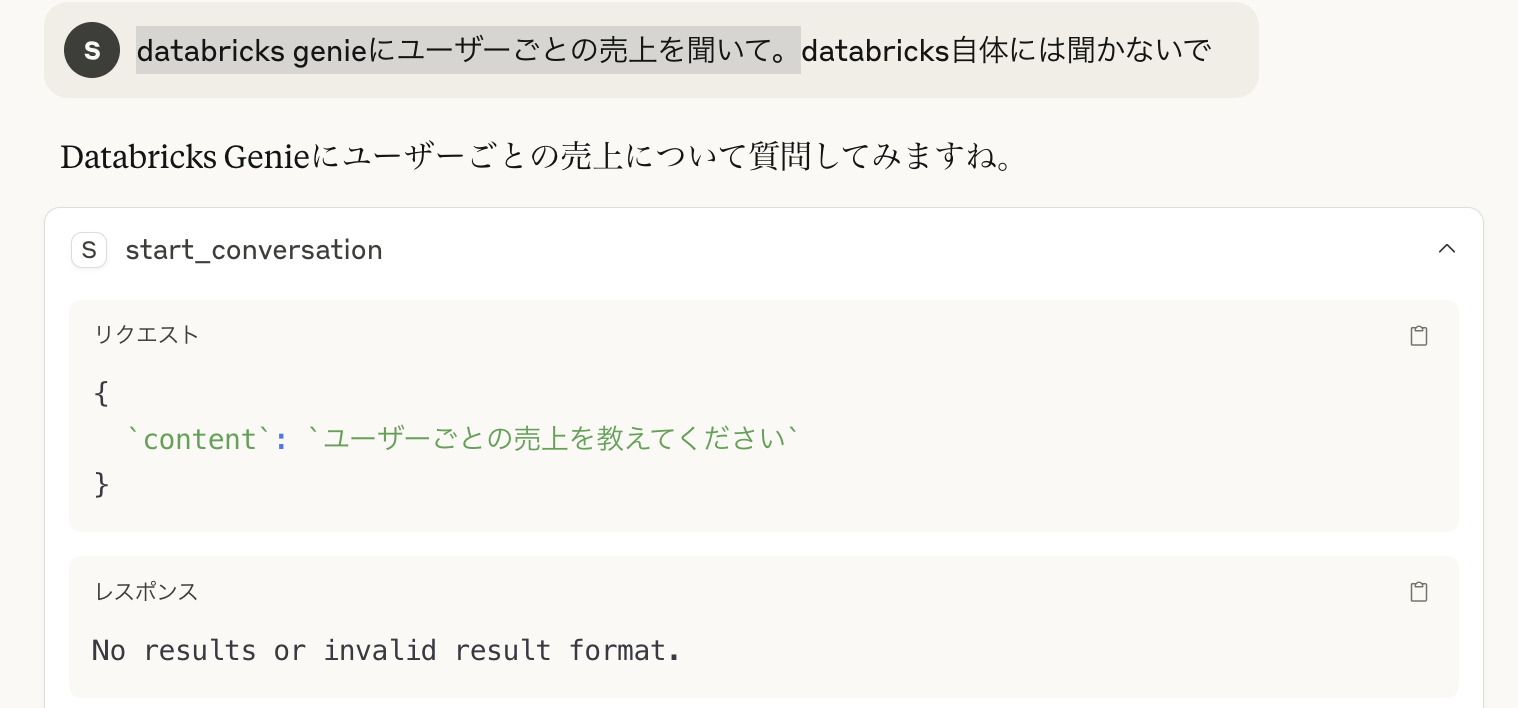
しかし、genieへの質問によってはレスポンスに失敗してしまっています。これは「データが出力されなかった」場合返すものがなくNullになってしまうからですね。この点はgenieを使うことの大きな問題点となっています。
5. まとめ
今回はgenieを使ったMCPを実践してみました。分析したいデータが決まっている場合はこちらも優秀ですね。
これからはdesktopでだけではなく、web上で使える技術も出てきましたので、さらに手軽にLLMを生かしたデータ分析ができる世界になるかも?
次回はdatabricksとclaudeの二つの接続方法をそれぞれ長所、短所をまとめていきたいと思います。

