チャーン(顧客離反)予測モデルを実装してみた

サブスクリプションビジネスにおいて、顧客の離脱を事前に予測できればどれほど心強いでしょうか。今回は1000名の顧客データを用いて、統計的検定と機械学習の両方のアプローチでチャーン予測モデルを構築しました。単なる技術解説ではなく、実際のビジネス現場で使える予測結果をいかに行動に移すかまで、実践的な視点でお伝えします。
目次
チャーン予測とは何か
チャーン(顧客離反)予測とは、現在の顧客の中で「将来的にサービスを解約しそうな顧客」を事前に特定する分析手法です。携帯電話会社やサブスクリプションサービスなどで広く活用されており、顧客維持コストを最適化し、売上損失を防ぐための重要な武器となっています。
新規顧客獲得コストが既存顧客維持コストよりも大幅にかかると言われる現在、チャーン予測は単なる分析ツールではなく、収益性向上の必須戦略と言えるでしょう。
データの概要確認
まず、分析対象となる1000名の顧客データの構造を確認してみましょう。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
from scipy.stats import chi2_contingency, ttest_ind
from sklearn.model_selection import train_test_split, cross_val_score, StratifiedKFold
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix, roc_auc_score, roc_curve
from sklearn.feature_selection import SelectKBest, chi2, f_classif
from sklearn.metrics import precision_score, recall_score, f1_score
import warnings
warnings.filterwarnings('ignore')
# サンプルデータの生成
np.random.seed(42)
n_customers = 1000
# 顧客属性データ生成
data = {
'customer_id': range(1, n_customers + 1),
'tenure': np.random.exponential(scale=24, size=n_customers), # 在籍期間(指数分布)
'monthly_charges': np.random.normal(loc=65, scale=20, size=n_customers), # 月額料金(正規分布)
'total_charges': np.random.gamma(shape=2, scale=500, size=n_customers), # 累積料金(ガンマ分布)
'contract_type': np.random.choice(['Month-to-month', 'One year', 'Two year'],
size=n_customers, p=[0.5, 0.3, 0.2]),
'payment_method': np.random.choice(['Credit card', 'Bank transfer', 'Electronic check', 'Mailed check'],
size=n_customers, p=[0.3, 0.2, 0.3, 0.2]),
'senior_citizen': np.random.binomial(1, 0.16, n_customers),
'partner': np.random.binomial(1, 0.48, n_customers),
'dependents': np.random.binomial(1, 0.3, n_customers),
'internet_service': np.random.choice(['DSL', 'Fiber optic', 'No'],
size=n_customers, p=[0.4, 0.4, 0.2]),
'online_security': np.random.binomial(1, 0.35, n_customers),
'tech_support': np.random.binomial(1, 0.29, n_customers),
'multiple_lines': np.random.binomial(1, 0.52, n_customers)
}
# データの中身の確認
df = pd.DataFrame(data)
print(df)データの中身
| customer\_id | tenure | monthly\_charges | total\_charges | contract\_type | payment\_method | senior\_citizen | partner | dependents | internet\_service | online\_security | tech\_support | multiple\_lines | user\_segment | churn |
| ------------ | --------- | ---------------- | -------------- | -------------- | ---------------- | --------------- | ------- | ---------- | ----------------- | ---------------- | ------------- | --------------- | ------------- | ----- |
| 1 | 11.262434 | 68.554020 | 215.284541 | One year | Mailed check | 0 | 0 | 1 | DSL | 0 | 1 | 0 | Standard | 0 |
| 2 | 72.242914 | 38.293113 | 780.831773 | One year | Electronic check | 0 | 0 | 0 | DSL | 1 | 0 | 1 | Standard | 1 |
| 3 | 31.601897 | 72.603957 | 887.688721 | One year | Bank transfer | 0 | 1 | 0 | No | 2 | 0 | 0 | Standard | 0 |
| 4 | 21.910621 | 77.211715 | 202.146501 | Two year | Credit card | 0 | 1 | 0 | No | 3 | 0 | 0 | Standard | 0 |
| 5 | 4.070997 | 76.195809 | 649.250704 | Month-to-month | Bank transfer | 0 | 0 | 1 | DSL | 4 | 0 | 0 | New Customer | 0 |各カラムの意味
- customer_id: 顧客ID
- tenure: 在籍期間(月)
- monthly_charges: 月額料金(ドル)
- total_charges: 累積料金(ドル)
- contract_type: 契約タイプ(Month-to-month/One year/Two year)
- payment_method: 決済方法(Credit card/Bank transfer/Electronic check/Mailed check)
- senior_citizen: シニア顧客フラグ(0/1)
- partner: パートナー有無(0/1)
- dependents: 扶養家族有無(0/1)
- internet_service: インターネットサービス種別(DSL/No/Fiber optic)
- online_security: オンラインセキュリティ利用(0/1)
- tech_support: テクニカルサポート利用(0/1)
- multiple_lines: 複数回線契約(0/1)
- user_segment: 顧客セグメント(Premium/New Customer/Senior/Family/Price-Sensitive/Standard)
- churn: チャーン(離脱)フラグ(0/1)
セグメント分類と基本統計
上記のカラムの1つに、user_segment: 顧客セグメントがありましたが、顧客セグメントは以下のようにして分類されています:
- Premium(4.0%): 月額80ドル超、在籍24ヶ月超、長期契約の高価値顧客
- New Customer(23.8%): 在籍6ヶ月未満の新規顧客
- Senior(11.9%): シニア世代の顧客
- Family(8.2%): パートナー・扶養家族を持つファミリー層
- Price-Sensitive(5.5%): 月額50ドル未満、月契約の価格重視顧客
- Standard(46.6%): 上記以外の一般顧客
以下に示すように、セグメントの詳細を確認してみます。
print("=== データ基本統計 ===")
print(f"総顧客数: {len(df)}")
print(f"チャーン率: {df['churn'].mean():.3f}")
print(f"平均在籍期間: {df['tenure'].mean():.1f}ヶ月")
print(f"平均月額料金: ${df['monthly_charges'].mean():.2f}")
# セグメント分布の確認
print(f"\\n=== ユーザーセグメント分布 ===")
segment_dist = df['user_segment'].value_counts()
for segment, count in segment_dist.items():
percentage = count / len(df) * 100
print(f"{segment}: {count}人 ({percentage:.1f}%)")
# セグメント別の基本統計
print(f"\\n=== セグメント別基本統計 ===")
segment_stats = df.groupby('user_segment').agg({
'churn': ['count', 'mean'],
'tenure': 'mean',
'monthly_charges': 'mean',
'total_charges': 'mean'
}).round(3)
segment_stats.columns = ['顧客数', 'チャーン率', '平均在籍期間', '平均月額料金', '平均累積料金']
print(segment_stats)
出力結果
=== データ基本統計 ===
総顧客数: 1000
チャーン率: 0.385
平均在籍期間: 23.3ヶ月
平均月額料金: $66.98
=== ユーザーセグメント分布 ===
Standard: 466人 (46.6%)
New Customer: 238人 (23.8%)
Senior: 119人 (11.9%)
Family: 82人 (8.2%)
Price-Sensitive: 55人 (5.5%)
Premium: 40人 (4.0%)
=== セグメント別基本統計 ===
顧客数 チャーン率 平均在籍期間 平均月額料金 平均累積料金
user_segment
Family 82 0.293 24.107 63.234 1018.265
New Customer 238 0.420 2.798 67.428 1000.705
Premium 40 0.250 49.610 91.906 956.969
Price-Sensitive 55 0.582 32.667 38.459 1150.416
Senior 119 0.336 30.097 65.864 1113.340
Standard 466 0.384 28.616 68.918 987.920統計的検定によるチャーン分析
それでは、セグメント別にチャーン分析を行っていき、離反セグメントを特定していきましょう。
# セグメント別チャーン分析
print(f"\\n=== セグメント別チャーン分析(統計的有意性)===")
segment_churn_analysis = []
for segment in df['user_segment'].unique():
segment_data = df[df['user_segment'] == segment]
other_data = df[df['user_segment'] != segment]
# セグメント内とセグメント外のチャーン率比較(カイ二乗検定)
contingency = pd.crosstab(
df['user_segment'] == segment,
df['churn'],
margins=False
)
chi2, p_value, _, _ = chi2_contingency(contingency)
analysis_row = {
'セグメント': segment,
'顧客数': len(segment_data),
'チャーン率': segment_data['churn'].mean(),
'平均在籍期間': segment_data['tenure'].mean(),
'平均月額料金': segment_data['monthly_charges'].mean(),
'カイ二乗統計量': chi2,
'p値': p_value,
'統計的有意性': 'Yes' if p_value < 0.05 else 'No'
}
segment_churn_analysis.append(analysis_row)
segment_analysis_df = pd.DataFrame(segment_churn_analysis)
segment_analysis_df = segment_analysis_df.round(3)
print(segment_analysis_df)出力結果=== セグメント別チャーン分析(統計的有意性)===
セグメント 顧客数 チャーン率 平均在籍期間 平均月額料金 カイ二乗統計量 p値 統計的有意性
0 Standard 466 0.384 28.616 68.918 0.000 1.000 No
1 New Customer 238 0.420 2.798 67.428 1.442 0.230 No
2 Price-Sensitive 55 0.582 32.667 38.459 8.663 0.003 Yes
3 Senior 119 0.336 30.097 65.864 1.138 0.286 No
4 Family 82 0.293 24.107 63.234 2.804 0.094 No
5 Premium 40 0.250 49.610 91.906 2.641 0.104 No
この出力結果を確認すると、セグメント: Price-Sensitive(月額50ドル未満、月契約の価格重視顧客)の離反が統計的に有意であることが分かりました。
また、どの特徴量がチャーンに統計的に有意な影響を与えているかも検証しました。
# 特徴量ごとのチャーン分析
print(f"\\n=== 特徴量ごとのチャーン分析 ===")
def analyze_feature_churn(df, feature_name):
"""特徴量別のチャーン分析を実行"""
feature_analysis = []
# バイナリ変数かどうかを判定
unique_values = df[feature_name].unique()
is_binary = len(unique_values) == 2 and set(unique_values) == {0, 1}
if df[feature_name].dtype in ['object', 'category'] or is_binary:
# カテゴリカル変数またはバイナリ変数の場合
for category in df[feature_name].unique():
category_data = df[df[feature_name] == category]
other_data = df[df[feature_name] != category]
# カイ二乗検定
contingency = pd.crosstab(
df[feature_name] == category,
df['churn'],
margins=False
)
if contingency.shape == (2, 2): # 2x2分割表の場合のみ
chi2, p_value, _, _ = chi2_contingency(contingency)
else:
chi2, p_value = np.nan, np.nan
analysis_row = {
'特徴量': feature_name,
'カテゴリ': str(category),
'顧客数': len(category_data),
'チャーン率': category_data['churn'].mean(),
'全体チャーン率': df['churn'].mean(),
'チャーン率差': category_data['churn'].mean() - df['churn'].mean(),
'カイ二乗統計量': chi2,
'p値': p_value,
'統計的有意性': 'Yes' if p_value < 0.05 else 'No'
}
feature_analysis.append(analysis_row)
else:
# 連続変数の場合
# 四分位数が重複していないかチェック
quartiles = df[feature_name].quantile([0.25, 0.5, 0.75]).values
unique_quartiles = len(np.unique(quartiles))
if unique_quartiles < 3:
# 四分位数が重複している場合は、カテゴリ化をスキップ
analysis_row = {
'特徴量': feature_name,
'カテゴリ': '分析不可(値の分散が小さい)',
'顧客数': len(df),
'チャーン率': df['churn'].mean(),
'全体チャーン率': df['churn'].mean(),
'チャーン率差': 0,
't統計量': np.nan,
'p値': np.nan,
'統計的有意性': 'No'
}
feature_analysis.append(analysis_row)
else:
# 四分位数で区切り
bins = [-np.inf, quartiles[0], quartiles[1], quartiles[2], np.inf]
labels = ['Q1(低)', 'Q2(中低)', 'Q3(中高)', 'Q4(高)']
df_temp = df.copy()
try:
df_temp[f'{feature_name}_quartile'] = pd.cut(df_temp[feature_name],
bins=bins, labels=labels,
duplicates='drop')
for quartile in labels:
quartile_data = df_temp[df_temp[f'{feature_name}_quartile'] == quartile]
if len(quartile_data) > 0:
# t検定(そのquartile vs その他)
quartile_churn = quartile_data['churn']
other_churn = df_temp[df_temp[f'{feature_name}_quartile'] != quartile]['churn']
if len(np.unique(quartile_churn)) > 1 and len(np.unique(other_churn)) > 1:
t_stat, p_value = ttest_ind(quartile_churn, other_churn)
else:
t_stat, p_value = np.nan, np.nan
analysis_row = {
'特徴量': feature_name,
'カテゴリ': quartile,
'顧客数': len(quartile_data),
'チャーン率': quartile_data['churn'].mean(),
'全体チャーン率': df['churn'].mean(),
'チャーン率差': quartile_data['churn'].mean() - df['churn'].mean(),
't統計量': t_stat,
'p値': p_value,
'統計的有意性': 'Yes' if p_value < 0.05 else 'No'
}
feature_analysis.append(analysis_row)
except ValueError as e:
# pd.cut()でエラーが発生した場合
analysis_row = {
'特徴量': feature_name,
'カテゴリ': f'分析エラー: {str(e)[:50]}...',
'顧客数': len(df),
'チャーン率': df['churn'].mean(),
'全体チャーン率': df['churn'].mean(),
'チャーン率差': 0,
't統計量': np.nan,
'p値': np.nan,
'統計的有意性': 'No'
}
feature_analysis.append(analysis_row)
return pd.DataFrame(feature_analysis)
# 分析対象の特徴量リスト
analysis_features = ['contract_type', 'payment_method', 'internet_service', 'user_segment',
'senior_citizen', 'partner', 'dependents', 'online_security',
'tech_support', 'multiple_lines', 'tenure', 'monthly_charges', 'total_charges']
# 各特徴量の分析実行
all_feature_analysis = []
for feature in analysis_features:
if feature in df.columns:
feature_df = analyze_feature_churn(df, feature)
all_feature_analysis.append(feature_df)
# 全ての特徴量分析結果を結合
combined_feature_analysis = pd.concat(all_feature_analysis, ignore_index=True)
combined_feature_analysis = combined_feature_analysis.round(3)
print("=== 特徴量別チャーン分析結果 ===")
combined_feature_analysis.tail(20)
出力結果
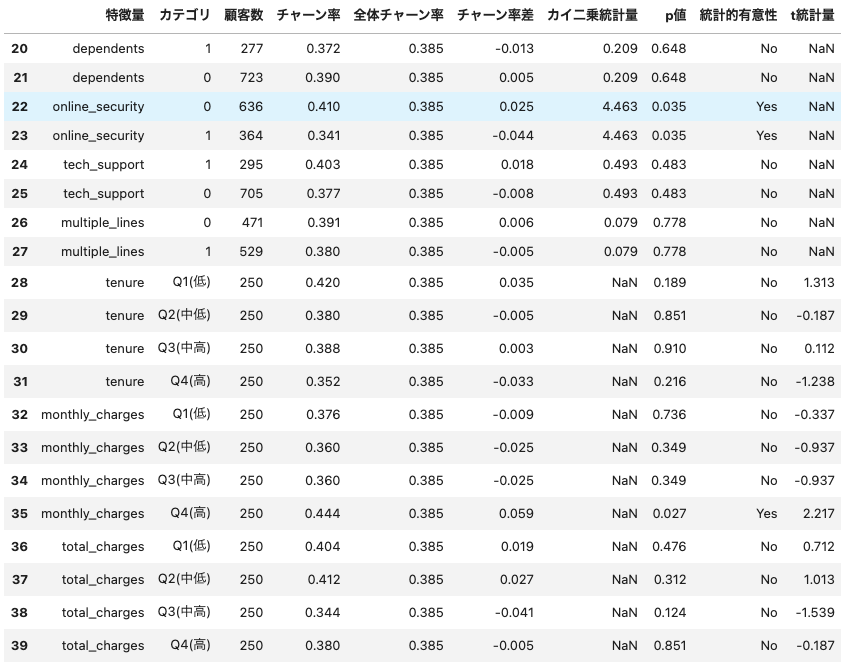
カラム数・レコード数が大きいので、カラム数を絞り、統計的有意性のカラムが ”Yes” のレコードのみを抽出してみましょう:
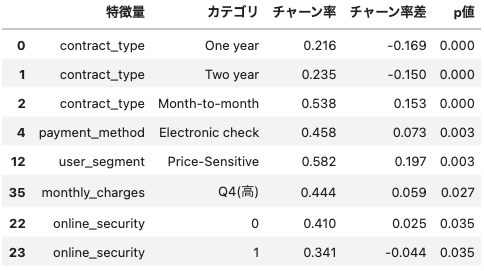
分析の結果、以下の特徴量がチャーンに統計的に有意な影響を与えていることが判明しました(p < 0.05):
主要な特徴量別のチャーン率
- 契約タイプ: Month-to-month契約(53.8%) vs One year契約(21.6%) vs Two year契約(23.5%)
- 決済方法: Electronic check(45.8%、+7.3%)
- 顧客セグメント: Price-Sensitive(58.2%、+19.7%)
- 月額料金: Q4高額層(44.4%、+5.9%)
- オンラインセキュリティ: セキュリティなし(41.0%、+2.5%) vs セキュリティあり(34.1%、-4.4%)
契約タイプが最も強い予測因子として確認され、月契約顧客の離脱率が年契約顧客の2倍以上となっています。Price-Sensitiveセグメントの高い離脱率や付加サービス利用による離脱抑制効果も統計的に有意な結果として得られました。
チャーン予測モデルの実装
それでは、機械学習アルゴリズムによるチャーン予測モデルの実装を行いましょう。今回は、ロジスティック回帰モデルを用いたいと思います。ロジスティック回帰モデルは、チャーン予測での結果の解釈がしやすく、ビジネス上のアクションに繋げやすいため、ベースラインモデルとして頻繁に採用されます。
# 機械学習モデルの準備
print(f"\\n=== 機械学習による予測分析 ===")
# データ前処理
le = LabelEncoder()
categorical_columns = ['contract_type', 'payment_method', 'internet_service', 'user_segment']
df_encoded = df.copy()
for col in categorical_columns:
df_encoded[col] = le.fit_transform(df_encoded[col])
# 特徴量とターゲットの分離(user_segmentも特徴量に含める)
feature_columns = ['tenure', 'monthly_charges', 'total_charges', 'contract_type',
'payment_method', 'senior_citizen', 'partner', 'dependents',
'internet_service', 'online_security', 'tech_support', 'multiple_lines',
'user_segment'] # セグメント情報を特徴量に追加
X = df_encoded[feature_columns]
y = df_encoded['churn']
# データ分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3,
random_state=42, stratify=y)
# テストデータにセグメント情報を保持
test_segments = df.iloc[X_test.index]['user_segment'].values
# 標準化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# ロジスティック回帰モデル
lr_model = LogisticRegression(random_state=42, max_iter=1000)
lr_model.fit(X_train_scaled, y_train)
# 予測
y_pred_proba_lr = lr_model.predict_proba(X_test_scaled)[:, 1]
y_pred_lr = lr_model.predict(X_test_scaled)
# セグメント別モデル性能評価
print(f"\\n=== セグメント別モデル性能 ===")
segment_performance = []
for segment in df['user_segment'].unique():
# テストデータでそのセグメントの顧客を抽出
segment_mask = test_segments == segment
if segment_mask.sum() > 0: # セグメント内に顧客がいる場合のみ
y_true_segment = y_test[segment_mask]
y_pred_segment = y_pred_lr[segment_mask]
y_pred_proba_segment = y_pred_proba_lr[segment_mask]
# 性能指標計算
if len(np.unique(y_true_segment)) > 1: # チャーン/非チャーンの両方がある場合のみAUC計算
auc = roc_auc_score(y_true_segment, y_pred_proba_segment)
else:
auc = np.nan
precision = precision_score(y_true_segment, y_pred_segment, zero_division=0)
recall = recall_score(y_true_segment, y_pred_segment, zero_division=0)
f1 = f1_score(y_true_segment, y_pred_segment, zero_division=0)
performance_row = {
'セグメント': segment,
'テスト顧客数': segment_mask.sum(),
'実際のチャーン率': y_true_segment.mean(),
'Precision': precision,
'Recall': recall,
'F1-Score': f1,
'ROC-AUC': auc
}
segment_performance.append(performance_row)
segment_performance_df = pd.DataFrame(segment_performance)
segment_performance_df = segment_performance_df.round(3)
segment_performance_df
精度結果
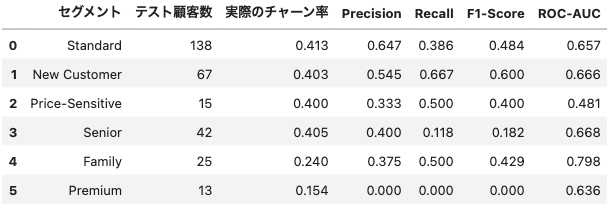
次に、どの特徴量が大きく寄与しているかも調べたいと思います。
# 特徴量重要度分析(機械学習ベース)
print(f"\\n=== 機械学習による特徴量重要度分析 ===")
# ロジスティック回帰の係数(絶対値)
lr_coeffs = np.abs(lr_model.coef_[0])
lr_importance_df = pd.DataFrame({
'特徴量': feature_columns,
'LogisticRegression係数絶対値': lr_coeffs
}).sort_values('LogisticRegression係数絶対値', ascending=False).reset_index(drop=True)
lr_importance_df
出力結果
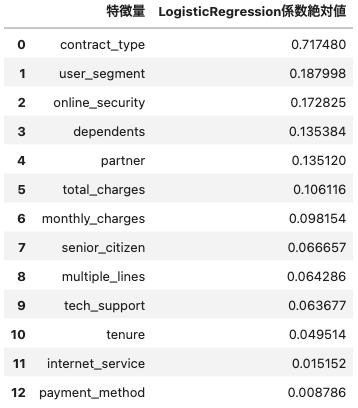
Logistic Regressionは契約形態・セグメントといった構造的要素を重視する傾向があります。また、Price-Sensitiveセグメントの予測精度(ROC-AUC 0.481)が低いことから、価格重視顧客の行動予測の困難さも確認されました。
で、何が言えるの?
今まで、いろいろな分析やモデルの実装を行ってきましたが、これらの結果から以下のことが発見されました。
発見1: 契約形態が最強の予測因子
統計的検定でもLogistic Regressionでも、契約タイプが最も重要な要因として検出されました。月契約顧客は年契約顧客の2.3倍離脱しやすく、これは契約による心理的コミットメントの差を示しています。
発見2: 価格重視顧客の危険性
Price-Sensitiveセグメントは統計的に有意に高い離脱率(58.2%)を示しました。これは「価格で獲得した顧客は価格で失う」という古典的なマーケティング原則の実証です。
発見3: 付加サービスの離脱抑制効果
オンラインセキュリティ利用顧客の離脱率が有意に低い結果は、付加サービスによるロックイン効果を示唆しています。
結局、何を提案すればいいの?
分析結果を踏まえ、具体的なアクションプランを以下に示すように提案します:
Price-Sensitiveセグメントへの緊急対応
- 長期契約への移行インセンティブ提供(例:1年契約で月額10%割引)
- 価値提案の再構築(安さ以外のメリット訴求)
- 競合対抗策の準備
新規顧客のオンボーディング強化
- 入会後30日、60日、90日の段階的フォローアップ
- 早期エンゲージメント施策(チュートリアル、サポート電話など)
- 初回利用体験の改善
契約形態の改善
- 月契約から年契約への移行促進キャンペーン
- 年契約の特典拡充
- 契約更新時の自動リテンション施策
MAツールを活用した自動化施策
チャーン予測の結果をMAツール(Marketing Automation)に連携することで、効率的な顧客維持施策を実現できます:
# MAツール連携のためのリスク顧客データ出力
def export_for_ma_tool(model, customer_data, customer_info):
"""
MAツール向けの高リスク顧客リスト生成
"""
risk_scores = model.predict_proba(customer_data)[:, 1]
ma_export = pd.DataFrame({
'customer_id': customer_info['customer_id'],
'email': customer_info['email'], # 実際のデータでは顧客メールアドレス
'segment': customer_info['user_segment'],
'churn_probability': risk_scores,
'risk_level': ['High' if score > 0.7 else 'Medium' if score > 0.3 else 'Low'
for score in risk_scores],
'recommended_action': [
'immediate_retention_call' if score > 0.7 else
'targeted_email_campaign' if score > 0.3 else
'standard_nurture'
for score in risk_scores
]
})
return ma_export
# セグメント別自動キャンペーンのトリガー設定例
campaign_triggers = {
'Price-Sensitive': {
'trigger': 'churn_probability > 0.5',
'action': '長期契約オファーメール配信',
'timing': '即座'
},
'New Customer': {
'trigger': 'tenure < 90 AND churn_probability > 0.4',
'action': 'オンボーディング強化シーケンス',
'timing': '7日以内'
},
'Standard': {
'trigger': 'churn_probability > 0.6',
'action': 'カスタマーサクセス担当による電話フォロー',
'timing': '3日以内'
}
}具体的なMA連携施策
- 自動セグメンテーション: 予測結果に基づいて顧客を自動的にリスクレベル別にタグ付け
- トリガーベース施策: チャーン確率が閾値を超えた顧客に自動的にリテンション施策を実行
- パーソナライズド配信: セグメント別に最適化されたメッセージを自動配信
- 効果測定: A/Bテストによる施策効果の継続的改善
例えば、BrazeやHubSpot、Salesforce Marketing Cloudなどのツールに予測結果を連携し、以下のような自動化を実現:
- Price-Sensitiveセグメント: チャーン確率50%超で長期契約割引オファーを自動配信
- New Customerセグメント: 在籍90日未満かつチャーン確率40%超でオンボーディング強化メールシーケンスを自動開始
- 高リスク顧客全般: チャーン確率70%超でカスタマーサクセス担当に自動アラートを送信
まとめ
チャーン予測は単なる「離脱しそうな顧客を見つけるツール」ではありません。それは企業が持つ顧客との関係性を数値化し、ビジネス戦略の意思決定を支える重要な羅針盤です。
重要なのは、組織全体でチャーン予測の結果を「明日の行動」に変える仕組みを作ることです。マーケティング部門、カスタマーサクセス部門、そして経営陣が一体となって、顧客一人ひとりに最適なタイミングで最適なアプローチを届ける。これこそが、データドリブンなカスタマーエクスペリエンスの真髄だと考えています。
あなたの会社でも、明日からチャーン予測を「作って終わり」ではなく、「使い倒すためのツール」として位置づけてみてください。きっと、顧客との関係性に対する新しい視点が生まれるはずです。




