PythonでEDAを自動化!ydata-profiling・Sweetviz・AutoViz徹底比較
この記事では、代表的な3つのライブラリydata-profiling・Sweetviz・AutoVizについて紹介します
はじめに
データ分析や機械学習の前に欠かせない工程といえば EDA(探索的データ分析:Exploratory Data Analysis) です。しかし、毎回ヒストグラムや相関行列を手作業で描くのは大変ですよね。
そこで登場するのが、自動でデータの特徴を可視化・要約してくれるEDA支援ライブラリです。
この記事では、代表的な3つのライブラリydata-profiling・Sweetviz・AutoVizについて紹介します
各ライブラリの説明
ydata-profiling
最も歴史が長く、有名なEDA自動化ツール。
データセットを渡すだけで、統計量・欠損値・相関・分布・型の推定などを網羅したHTMLレポートを生成します。
レポートは見やすく整理されており、データ品質のチェックや前処理方針の検討に最適です。
また、Pandasとの親和性が高く、1行で簡単にEDAを完結できる点が魅力です。
Sweetviz
デザイン性が高く、比較に特化したEDAライブラリ。
トレーニングデータとテストデータ、あるいは異なるグループのデータを簡単に比較できます。
グラフィカルで直感的なレポートをHTMLとして出力し、データの偏りやバランスを視覚的に把握可能です。
特に分類モデル開発前のデータ検証ステップにおいて非常に有用です。
AutoViz
最小限のコードで豊富な可視化を自動生成するEDAツール。
ターゲット変数を指定すれば、特徴量ごとの分布・関係性・重要度などを自動で描画します。
グラフ生成に重点を置いており、Notebook環境でのデータ理解を視覚的に支援します。
大規模データにも対応しており、短時間で全体像を掴みたい分析初期段階に適しています。
各ライブラリの比較
ydata-profiling
メリット
- 統計量や欠損値、相関などを自動で詳細に分析。
- 1行でHTMLレポートを生成でき、手間が少ない。
- データ品質チェックや初期探索に最適。
デメリット
- 大規模データでは処理が重くなることがある。
- ビジュアルよりも統計的レポート寄り。
- カスタマイズ性が限定的。
Sweetviz
メリット
- トレーニングデータとテストデータの比較分析に特化。
- デザイン性が高く、グラフが見やすい。
- レポートの共有が簡単(HTML形式)。
デメリット
- 統計分析の深さはydata-profilingに劣る。
- NumPyなどとの互換性問題が出る場合がある。
- カスタム集計や数値調整が難しい。
AutoViz
メリット
- コード1〜2行で豊富な可視化グラフを自動生成。
- 目的変数を指定するだけで関連性を可視化。
- Notebook環境で軽快に動作。
デメリット
- HTMLレポート形式ではなくNotebook上での出力中心。
- 細かい調整(フォント、色など)が難しい。
- 他ツールに比べて統計情報の出力は控えめ。
ハンズオン
実装環境:今回はGoogle Colabratoryを使用します。
使用するデータ:今回はタイタニック号のデータを使用します。
import seaborn as sns
df = sns.load_dataset("titanic")ydata-profiling
!pip install ydata-profiling
from ydata_profiling import ProfileReport
profile = ProfileReport(
df,
title="Data Profile Report",
explorative=True, # 追加の可視化・相関などを有効化
minimal=False # 大規模なら True にして軽量化
)
profile.to_file("ydata_profile.html")こちらのコードを実行して、画面右の「ファイル」をクリックしてください。

中身を確認するとhtmlファイルが作成されているので。こちらをダウンロードして、ローカルで開いてみてください。
以下のようにレポートが作成されていたら成功です。

Sweetviz
こちらのコードを実行したら、一度セッションを再起動してください。
※これを実行しないとSweetviz と NumPy のバージョン不整合によってエラーが発生します。
!pip install numpy==1.26.4 sweetviz --upgrade --quietimport sweetviz as sv
report = sv.analyze(df)
# レポートを生成(HTMLファイル)
report.show_html('sweetviz_report.html')こちらのコードを実行して、画面右の「ファイル」をクリックしてください。
中身を確認するとhtmlファイルが作成されているので。こちらをダウンロードして、ローカルで開いてみてください。
以下のようにレポートが作成されていたら成功です。
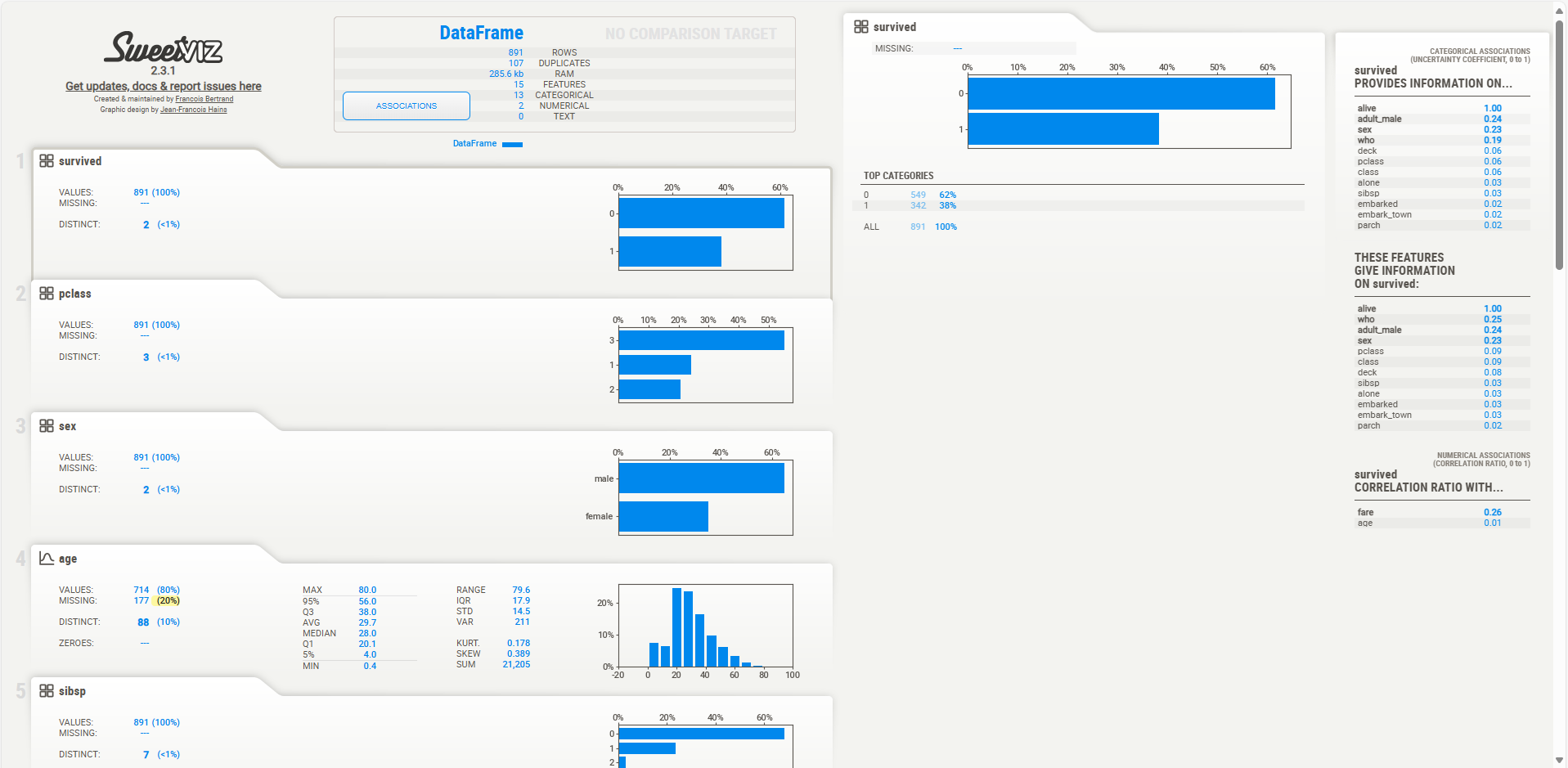
AutoViz
!pip install -U autoviz --quiet
from autoviz.AutoViz_Class import AutoViz_Class
AV = AutoViz_Class()
viz_df = AV.AutoViz(
filename="", # 直接 df を渡すので空文字
dfte=df, # ← DataFrame を渡す
depVar="alive", # 目的変数が無ければ空文字
header=0,
verbose=0,
lowess=False,
chart_format="svg", # "svg" または "png"
max_rows_analyzed=300000,
max_cols_analyzed=200
)実行結果として以下のような表が生成されれば成功です。

おわりに
本記事では、代表的なEDA自動化ライブラリであるydata-profiling・Sweetviz・AutoViz の特徴を比較して紹介しました。
どのツールも「数行のコードでEDAを自動化できる」という共通点を持ちながら、それぞれ得意分野が異なります。
これらのツールを使い分けることで、分析の効率を大幅に高め、より良い洞察を得ることができるでしょう。



