Databricks LakeFlow 調査・活用ガイド
本資料では、LakeFlowのGA機能(Connect / Declarative Pipelines / Jobs)の説明に加え、Salesforceデータの取り込みデモ、業務での具体的ユースケース、他社ツールとの比較、さらにAgent Bricksとの連携可能性まで幅広く整理しています。
目次
1 機能の説明
機能の説明
Databricks Lakeflow は、データエンジニアリングに必要な機能(データの取り込み・変換・実行・管理)を統合した オールインワンのパイプライン構築・運用基盤です。
主な構成要素(現在GA済のもの)

※GUIベースの「Lakeflow Designer」は現在Private Preview(限定公開)であり、一般公開されていません。
2 メリット・デメリット
メリット(旧構成との比較)
一体化されたエンドツーエンド機能
→ これまで別々だった ingestion / transform / scheduling を1つの構成で完結
ノーコードでの取り込みが可能(Lakeflow Connect)
→ SalesforceやWorkdayなどのSaaSデータも、コード不要で取得・CDC管理可能
ガバナンス一体化(Unity Catalog)
→ パイプラインの実行ログ、リネージ、アクセス制御を自動管理
開発体験が向上
→ Declarative Pipelinesでは、再利用性のある関数的パイプライン定義が可能
デメリット・注意点
- Unity Catalog前提での運用が強く求められる
- 既存パイプライン(ノートブックやDLT)からの移行には調整が必要
- Lakeflow Designerなど一部機能は未公開またはプレビュー中
3 アーキテクチャの概要
[ データソース (Salesforce, MySQL, etc.) ]
↓
Lakeflow Connect (ノーコード, CDC対応)
↓
Declarative Pipelines (SQL/Python, DAG定義)
↓
Lakeflow Jobs (依存制御, スケジュール)
↓
[ Delta Lake + Unity Catalog (ガバナンス層) ]
- Compute層:Databricksのサーバーレス Spark エンジン
- ガバナンス層:Unity Catalog によるセキュリティ・リネージ統合
- ストレージ:Delta形式のストレージレイヤに書き込み
4 実際の使い方、動かし方
利用手順(公開機能のみ)
- Lakeflow Connectのセットアップ
- GUIでSalesforceなど接続 → テーブル選択 → CDC or フルロード指定
- Databricks Lakeflow Connect(公式ドキュメント)
- Declarative Pipelineの定義
- SQLやPythonを使って、読み込み・加工処理を定義(再利用可)
- Lakeflow Declarative Pipelines(公式ドキュメント)
- Lakeflow Jobsでのスケジュール設定
- 実行順・依存関係を定義し、毎日/毎時での実行や失敗通知などを管理
- Lakeflow Jobs(公式ドキュメント)
動かしている動画(GA公開済)
Databricks公式による Lakeflow の全体デモ(Data + AI Summit 2025)
https://www.databricks.com/jp/resources/demos/videos/lakeflow-demo
https://www.youtube.com/watch?v=84w7mO6IB
LakeFlow Connect with Salesforce デモ手順
1. Data Ingestion に移動
- Databricksの左側メニューから「Data Ingestion」へ移動
2. データソースとして Salesforce を選択
- 「Databricks connectors」で Salesforce を選択
3. Ingestion Pipeline を作成
- Pipeline 名を入力(例:
salesforce_account_pipeline) - Event log の保存先(Catalog / Schema)を選択(例:
main.default) - 「Connection to the source」で「+ Create connection」をクリック
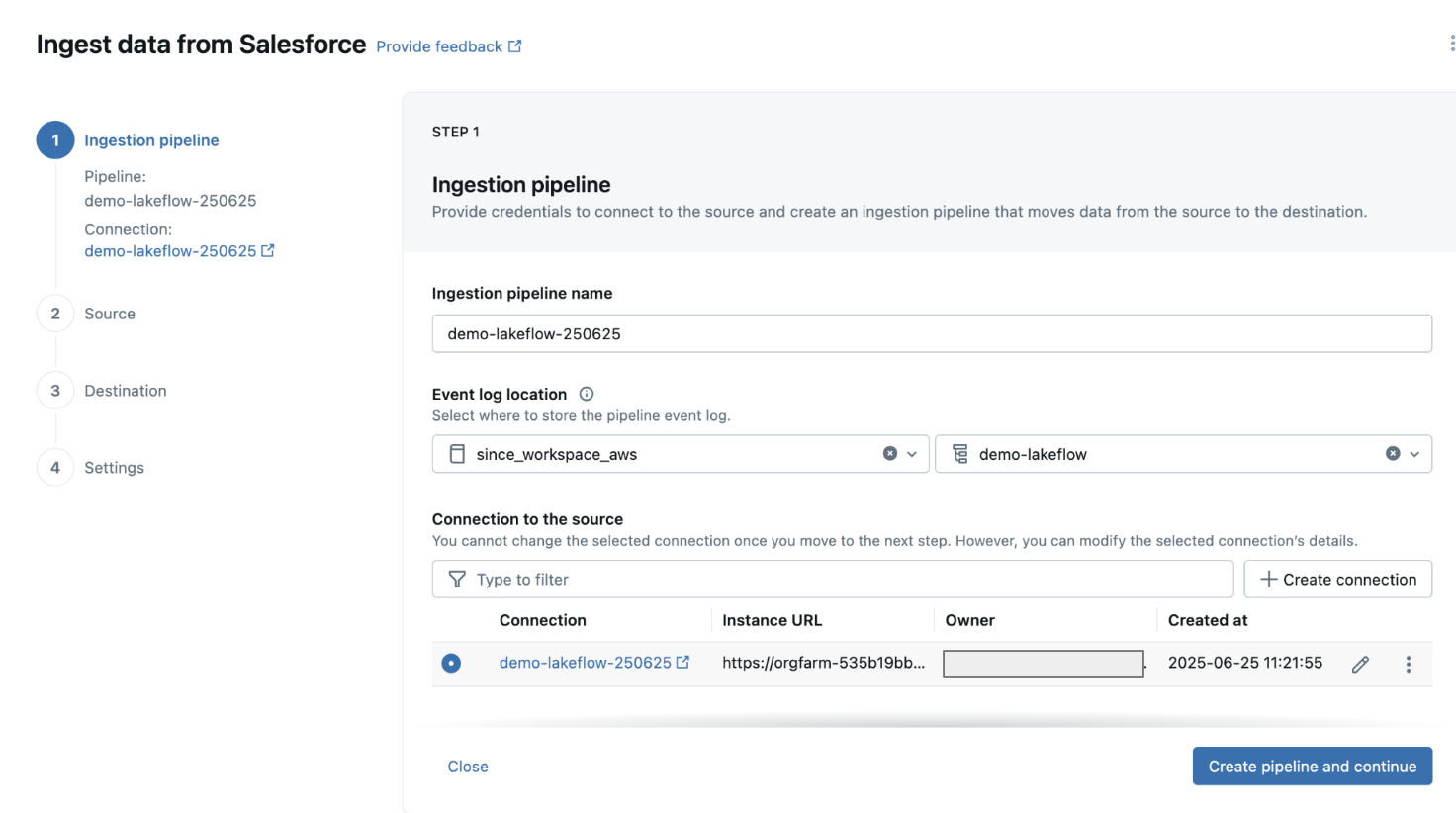
4. Salesforce Developer Edition アカウントを作成
- https://developer.salesforce.com/signup にアクセスして無料登録
- 登録後、メールで受信したリンクからログインし、初回パスワードを設定
5. Databricks に Salesforce 接続情報を入力
- 「Create connection」を選択し、接続名を入力
- 「Authenticate and create connection」をクリックして接続を完了
6. 接続が成功したら「Create pipeline and continue」をクリック
7. Source 画面でオブジェクトを選択
- Salesforceのオブジェクト一覧が表示される
- 例として
Accountを選択し、「Next」で進む

8. Destination(保存先)の指定
- Databricks上の保存先テーブルを指定
- Catalog / Schema / Table 名を定義(例:
main.default.salesforce_accounts) - 「Save and continue」

9. Settings の確認
- スケジューリング設定やインクリメンタル取り込みの有無を確認
- デフォルトのままでも構わない
- 「Save and run pipeline」でパイプラインを起動
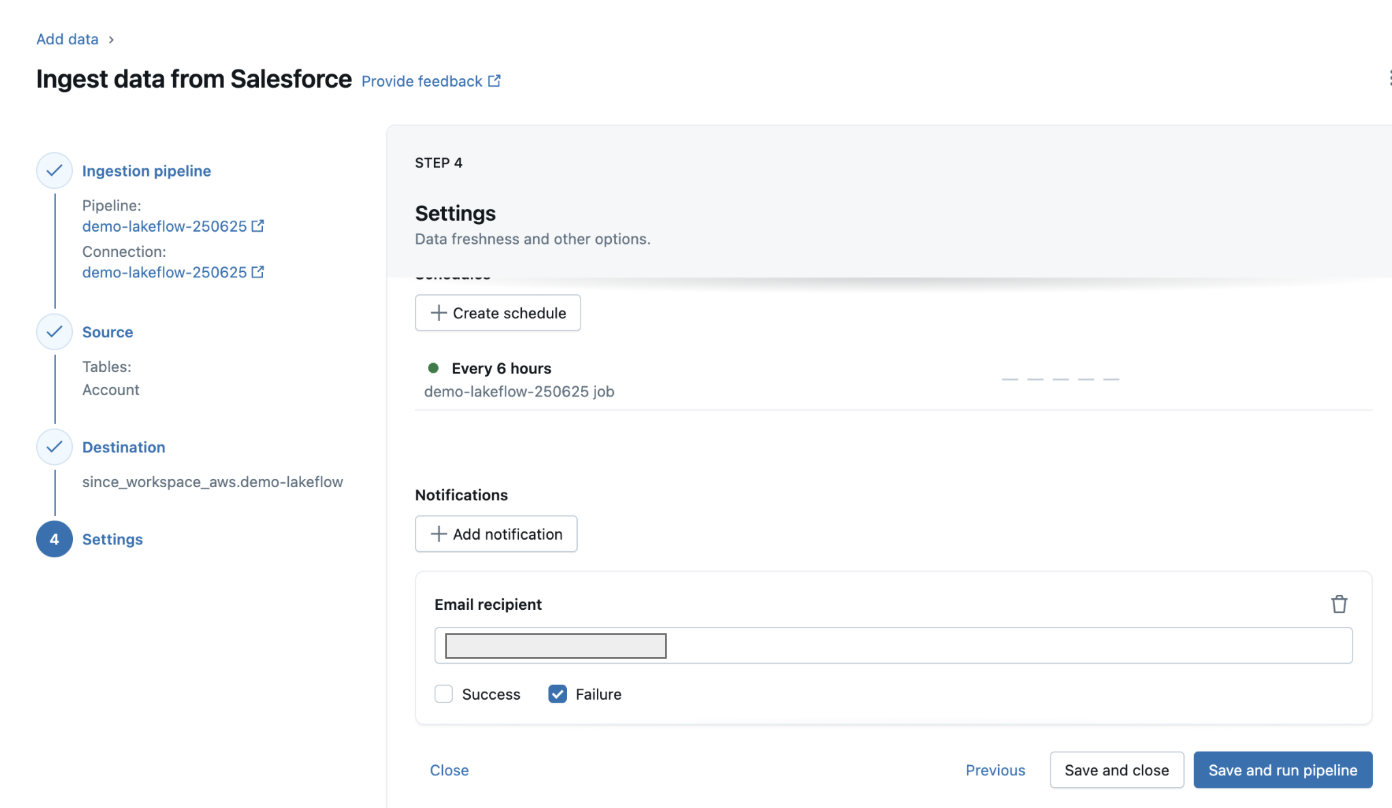
10. 実行と結果の確認
- 完了

5 業務での用途・ユースケース・シナリオ
LakeFlow Connectは、Databricks上でノーコード/ローコードでデータパイプラインを構築・実行できる機能です。特にSaaS連携に強く、Salesforceなどの外部サービスとデータレイクを簡潔に接続できます。
代表的なユースケースは、CRMと分析基盤を連携させるシナリオです。たとえばSalesforceに保存された商談情報(Opportunity)や顧客情報(Account)を定期的に取り込み、DatabricksのDeltaテーブルに蓄積することで、営業パフォーマンスの可視化や売上予測分析が可能になります。
また、マーケティング部門ではリード(Lead)情報を他のチャネルデータ(例:広告ログ、Webアクセス履歴)と結合し、ファネルごとの効果測定や施策評価を行うケースにも適しています。
LakeFlow Connectは、従来のETLと異なり、コードをほとんど書かずにスケーラブルなパイプラインを構築できるため、業務部門やアナリストでも活用しやすく、データ統合と分析のスピードを大幅に向上させることができます。
6 他社の類似サービス(比較)

7 参考URL
公式ドキュメント
Databricks Lakeflow 製品概要
https://www.databricks.com/product/lakeflow
Lakeflow Connect
Lakeflow Pipelines
Lakeflow Jobs
先行のブログ記事(GA対象のみ)
- Introducing Databricks Lakeflow
- Lakeflow Connect GA 発表
- https://www.databricks.com/jp/resources/demos/videos/lakeflow-demo
- https://www.youtube.com/watch?v=84w7mO6IB30
7 LakeFlow ✖️ Agent Bricks
現時点(2025年6月)では、LakeFlow に Agent Bricks の作業を直接パイプラインステップとして組み込むことはできません。
8 まとめ
Databricks LakeFlowは、データパイプラインの「設計・実行・管理」を1つの統合基盤で実現する仕組みであり、特にConnect / Pipelines / Jobs の3機能によって、従来分断されがちだったETLプロセスを一貫性と再利用性をもって構築できる点が大きな特長です。
GUI中心のノーコードデータ連携(LakeFlow Connect)、宣言的で保守性の高い変換処理(Declarative Pipelines)、スケジューラ・依存制御を含む運用管理機能(LakeFlow Jobs)により、非エンジニアを含む部門でもデータ統合を推進しやすい構成となっています。
一方で、Unity Catalog前提での設計、既存資産からの移行設計、LakeFlow Designer(GUI設計ツール)の未公開など、導入には段階的な移行戦略と社内権限整備が求められます。
現在のDatabricksユーザー、もしくはこれから一気通貫のデータ基盤を整備したい組織にとっては、LakeFlowは統合型データパイプライン基盤として現実的かつ将来性のある選択肢です。
