Dataiku予測結果タブの解説_2

目次
はじめに
Dataikuを使えば、コードを書かずにクリックだけで機械学習(ML)モデルを作成できます。しかし、いざモデルを作ってみて、こう思ったことはないでしょうか。
「結果画面になんかすごいグラフが出たけど、これって結局いいの?悪いの?」
私自身、AutoMLでモデルを作るところまではスムーズにいけたものの、表示された「Results」タブの詳細な数値をどう判断すればいいのか分からず、立ち止まってしまいました。
そこで今回は、Dataikuの学習コンテンツ「Machine Learning Basics」を通して学んだ、結果画面の正しい見方とモデル精度の判断基準についてアウトプットします。同じように「画面の見方が分からない」と悩んでいる方の参考になれば幸いです。
なお、機械学習には大きく「分類(Classification)」と「回帰(Regression)」という2種類のタスクがあり、Dataikuの結果画面に表示される項目はタスクの種類によって異なります。今回扱う「再入院予測」は2値分類モデルであるため、この記事では分類モデル固有の評価画面を中心に解説します。
この記事では、PERFORMANCEタブとMODEL INFORMATIONタブに含まれる以下の6つの画面について解説します。
- Confusion Matrix(混同行列) ― 予測の正解・不正解を4つに分類して確認する
- Decision chart(決定チャート) ― しきい値を変えたときの各指標の変化と、ビジネス損益を可視化する
- Lift chart(リフトチャート) ― モデルを使った優先順位付けの効果を測る
- Density chart(密度チャート) ― モデルが2つのクラスをどれだけ分離できているかを確認する
- Features(特徴量) ― どの変数が採用・除外されたかを確認する
- Algorithm(アルゴリズム) ― モデルの学習設定と使用データの統計を確認する
Confusion matrix
混同行列(Confusion Matrix)とは、ターゲット変数の実測値と予測値を対比させた表です。Dataikuでは、この表に加えて、適合率(Precision)・再現率(Recall)・F1スコアなどの関連指標も確認できます。
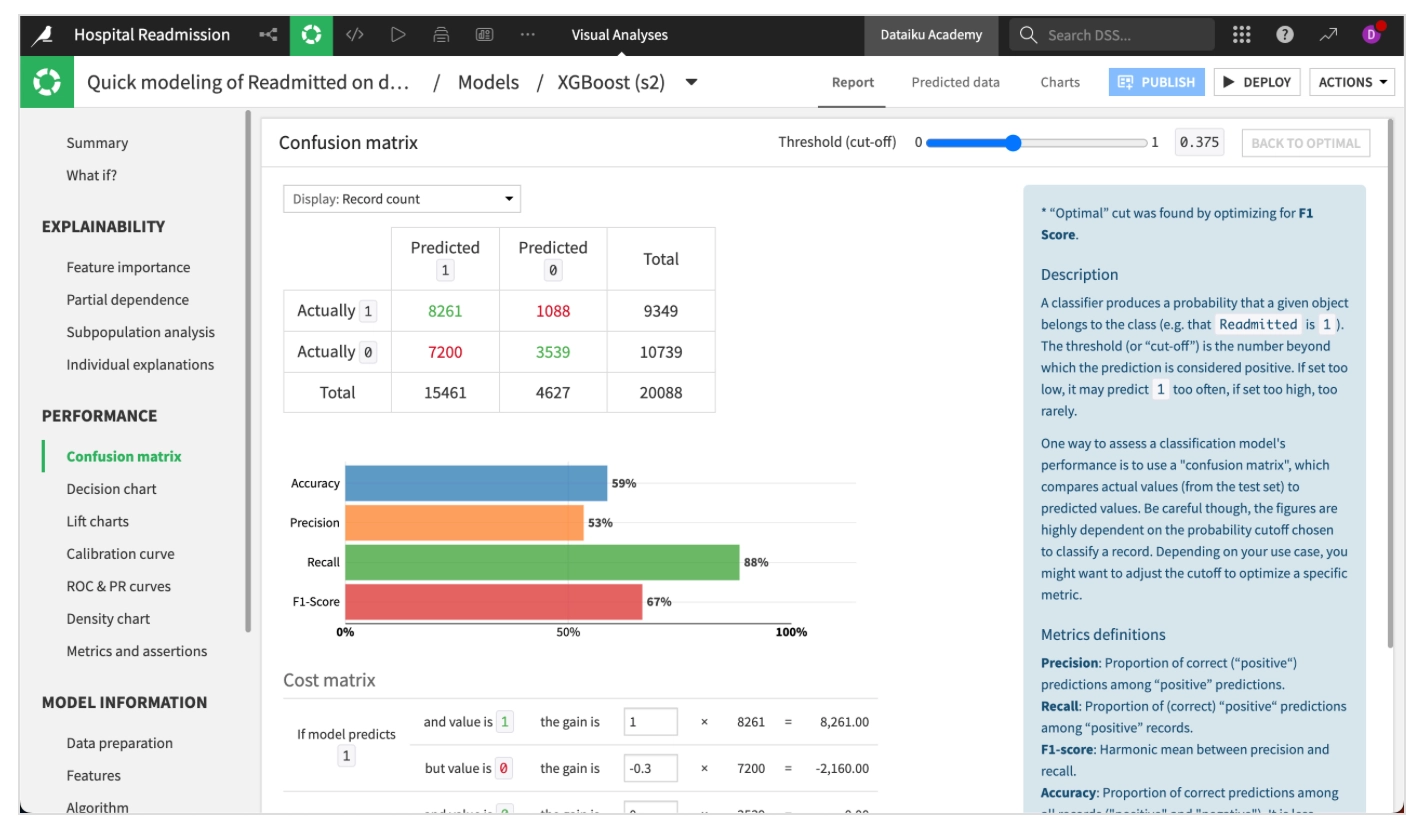
- 表(Matrix)の読み方:4つの数字の意味
画面中央の表は、「実際の正解(縦軸)」と「モデルの予測(横軸)」の組み合わせを示しています。
Actually 1 (実際は再入院あり)
- Predicted 1(緑の数字:8,261)― 正解(True Positive)
- 「再入院する」と予測し、実際に再入院した件数です。この数が多いほど、モデルの性能が高いといえます。
- Predicted 0(赤の数字:1,088)― 見逃し(False Negative)
- 「再入院しない」と予測したにもかかわらず、実際には再入院してしまった件数です。医療の現場では、このミスが最も深刻な影響をもたらします。
Actually 0 (実際は再入院なし)
- Predicted 1(赤の数字:7,200)― 誤検知・空振り(False Positive)
- 「再入院する」と予測したにもかかわらず、実際には何も起きなかった件数です。この数が多いと、不要な検査や連絡が増え、現場の負担につながります。
- Predicted 0(緑の数字:3,539)― 正解(True Negative)
- 「再入院しない」と予測し、実際に再入院しなかった件数です。
まとめ: 見逃し(1,088件)はかなり抑えられている一方で、空振り(7,200件)が非常に多い状態です。全体として「念のため危険と判定しておく」傾向が強いモデルになっています。
- 棒グラフ(Metrics)の読み方
表の下にある棒グラフは、上記の数字をもとに算出した各評価指標を示しています。
Accuracy (正解率): 59%
- 全予測のうち、正しく判定できた割合です。今回は空振りが多いため、59%とやや低い結果になっています。
Precision (適合率): 53%
- 「再入院する」と予測した中で、実際にそうだった割合です。この値が低いと、警報の半数が外れる状態になります。
Recall (再現率): 88% ★重要
- 実際に再入院した患者のうち、何割をモデルが検出できたかを示します。このモデルの最大の特徴はこの値の高さです。見逃しを極力減らしたい医療現場では、再現率を最優先に評価することが多くあります。
F1-Score: 67%
- 適合率と再現率のバランスを総合的に示す指標です。
- 上部のスライダー(Threshold)について
右上の Threshold (cut-off) 0.375 というスライダーは重要な設定項目です。
モデルは「この患者が再入院する確率は40%」といった形で確率値を出力しますが、その確率をどこから「1(再入院あり)」と判定するかを決める境界値、すなわちしきい値(カットオフ値)が必要です。
現在は 0.375(37.5%)以上 であれば「危険(1)」と判定する設定になっています。
- スライダーを右(1側)に動かすと: 判定基準が厳しくなり、空振り(False Positive)は減りますが、見逃し(False Negative)が増えます。
- スライダーを左(0側)に動かすと: 判定基準が緩くなり、見逃しは減りますが、空振りがさらに増えます。
この結果をどう評価するか
現在のモデルは、「空振りが多少増えても、とにかく見逃しを減らすこと(Recall重視)」を優先した設定になっています。これは、しきい値が低めに設定されていることが主な要因です。
なお、Dataikuではデフォルトで最適なカットオフ値における混同行列と関連指標が表示されます。カットオフ値を手動で変更した場合は、その変更が混同行列と各指標の両方にリアルタイムで反映されます。
Decision chart
「Decision chart(決定チャート)」タブには、考えられるすべてのカットオフ値に対するモデルのパフォーマンス指標がグラフ形式で表示されます。
これは、「しきい値(スライダー)を動かしたときに各指標がどのように変化するかを、一覧でまとめて確認できるグラフ」です。
先ほど混同行列(Confusion Matrix)の説明で「スライダーを動かすと数値が変わる」とお伝えしましたが、実際にスライダーを動かしながら一つひとつ確認するのは手間がかかります。このグラフでは、横軸にカットオフ値(0〜100%)をとり、それぞれの位置における各指標のスコアを線グラフで一度に確認できます。 以下では、各線の意味と、この画面の最大の特徴である「損益計算(Cost matrix)」について解説します。
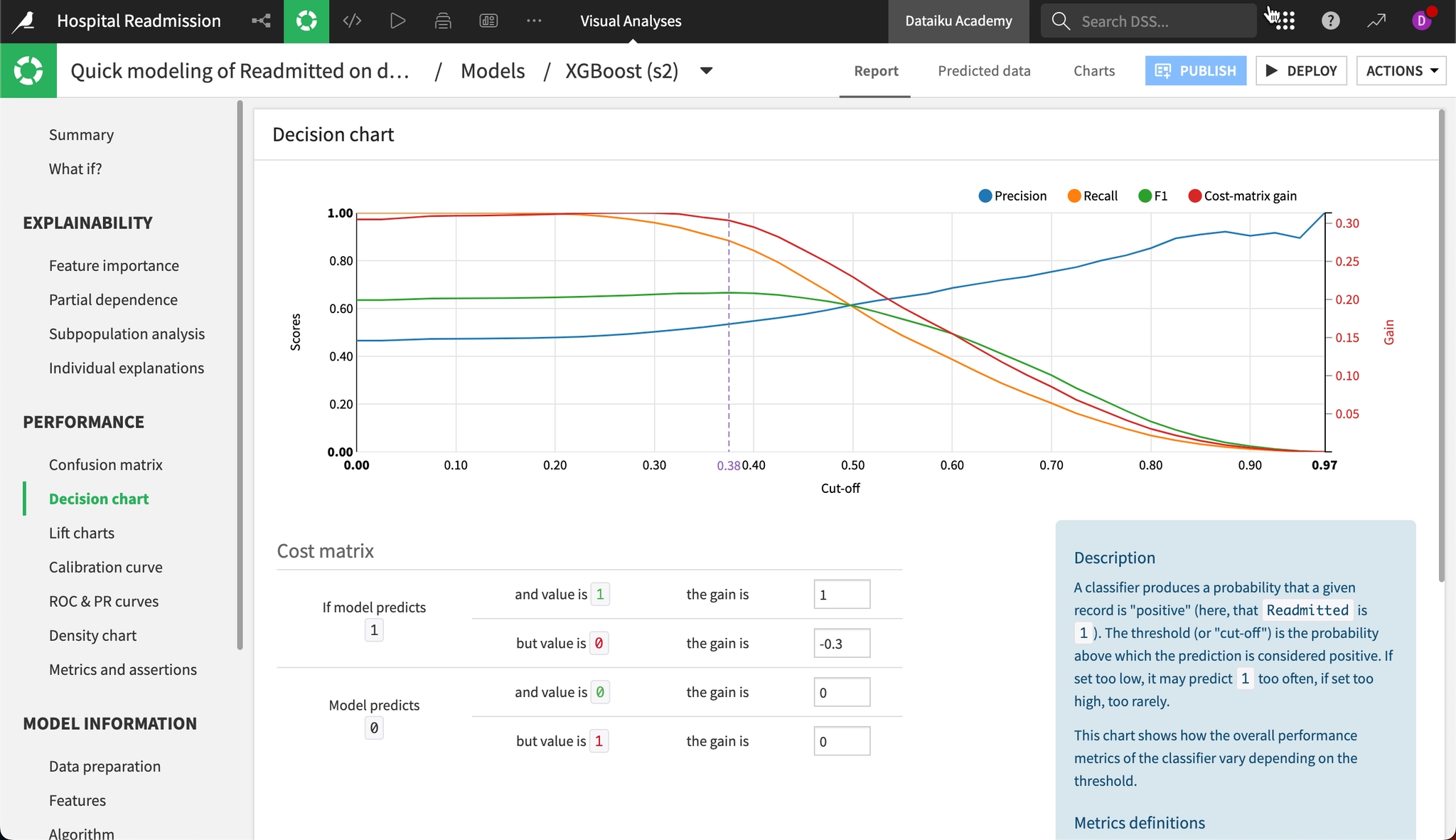
- グラフの線の見方(トレードオフの可視化)
横軸(Cut-off): カットオフ値(しきい値)を示します。左端が0%(すべてを陽性と判定)、右端が100%(非常に厳格な判定)です。
縦軸 (Scores): 各指標のスコア(0.0〜1.0)を示します。
各色の線は以下のように推移します。
オレンジ色:Recall(再現率/見逃しを減らす力)
- 推移: 右肩下がり ↘
- 意味: しきい値を厳しくするほど陽性と判定される件数が減るため、見逃しが増え、再現率は低下します。
青色:Precision(適合率/空振りを防ぐ力)
- 推移: 右肩上がり ↗
- 意味: しきい値を厳しくするほど、より確実な場合のみ陽性と判定されるため、適合率は上昇します。
緑色:F1 Score(バランス指標)
- 推移: 山なり
- 意味: 再現率と適合率のバランスが最もよい地点で頂点を迎えます。
- ※現在の点線(0.38付近)は、この緑の線が最も高くなる位置に引かれています。
- 赤い線と下の表:Cost Matrix(損益分岐点)
これがこの画面の最大の特徴です。単なる正解率ではなく、「**ビジネス的にどれだけの利益(または損失)が生じるか」**を数値化してグラフに表示しています。
下の表(Cost matrix)の設定内容
画面下半分では、各予測結果に対して「金銭的な価値」を設定します。
- If model predicts 1 and value is 1(正解・ヒット):
Gain is 1再入院を正しく予測できた場合、+1点(例:1万円の利益)とします。 - but value is 0(空振り・誤検知):
Gain is -0.3誤ってアラートを発報してしまった場合、-0.3点(例:3千円のコスト)とします。 ※なお、「見逃し(Predict 0, value 1)」と「正解(Predict 0, value 0)」のペナルティはいずれも0に設定されています。
赤い線(Cost-matrix gain)
この設定に基づき、カットオフ値ごとのトータル利益を描いたのが赤い線です(目盛りは右側の軸 Gain を参照してください)。
このグラフからわかること:
- 赤い線も、現在の点線(0.38付近)でほぼピークを迎えています。
- つまり、「F1スコア(統計的な最適解)」と「Cost matrix gain(ビジネス的な最適解)」が一致しており、非常にバランスのよいカットオフ値が選ばれていることがわかります。
- 実務での活用方法
ビジネスの現場では、F1スコア(緑)のピークと利益(赤)のピークが一致しないケースも多くあります。
例: 「空振りのコスト(-0.3)」をより高い「-2.0」などに設定した場合、赤い線のピークはより右側(慎重な判定)に移動します。
活用手順:
- 下の表に、実際のビジネスコスト(例:対応コスト500円、見逃し損失10,000円など)を入力する。
- 「赤い線が最も高くなっている地点(ピーク)」を探す。
- そのときの横軸の値(カットオフ値)を確認し、本番運用のしきい値として採用する。
この画面は、「数学的に正しいモデル」ではなく、「最も利益を最大化できる(または損失を最小化できる)運用ルールを決めるための画面」と捉えるとよいでしょう。
Lift charts
Lift chart(リフトチャート)やROC曲線は、機械学習モデルの性能を評価するための視覚的なツールです。グラフの起点における曲線の立ち上がりが急なほど、モデルの精度が高いことを示しています。
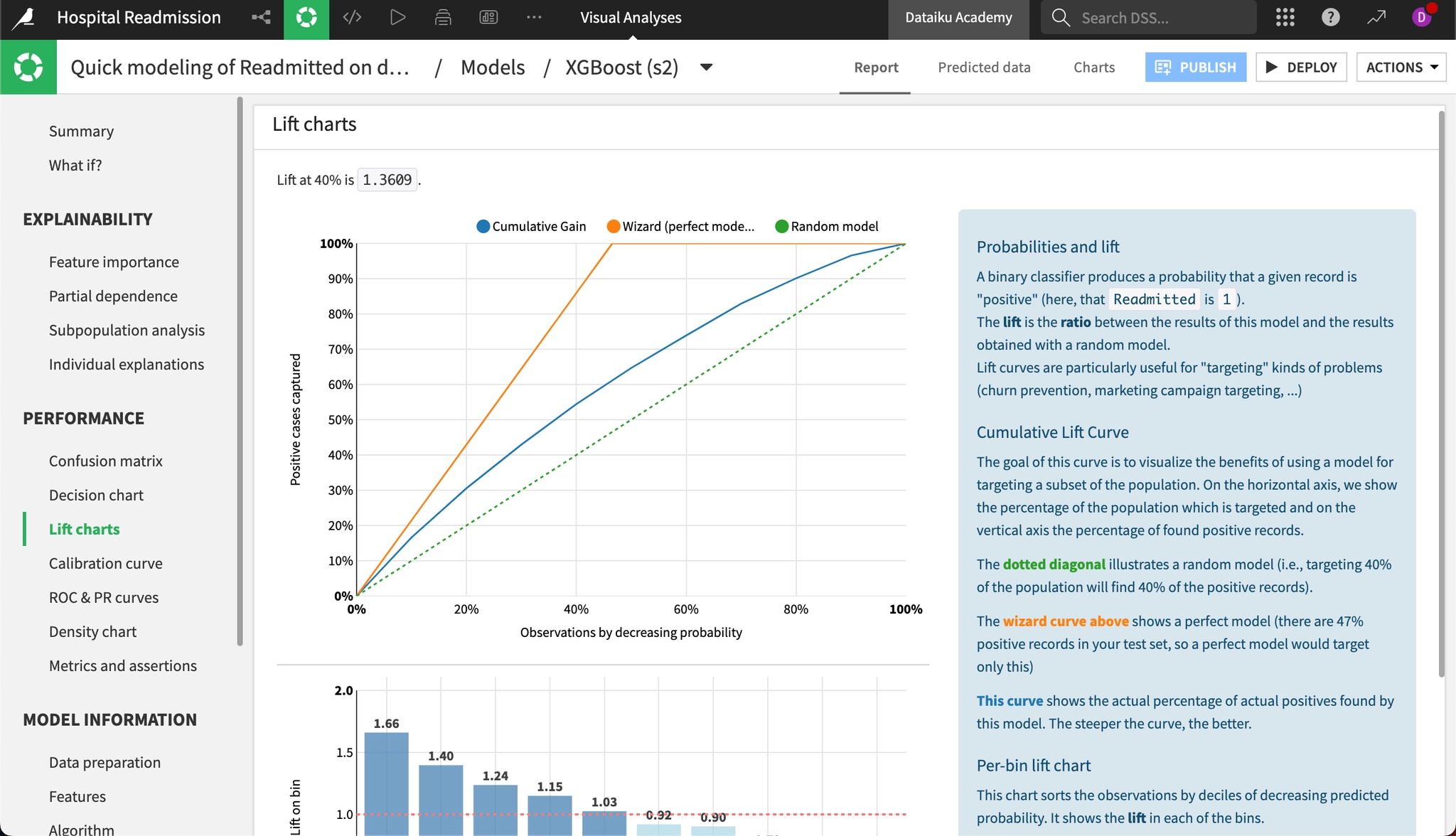
- 上のグラフ:Cumulative Gain(累積ゲインチャート)
「リストの上位からアプローチしていった時、正解をどれだけ早く回収できるか?」 を表しています。
- 横軸: 予測スコアが高い順に並べたデータの人数の割合(上位0% → 100%)。
- 縦軸: 全体の正解者(再入院する人)のうち、何%を検出できたか。
3本の線の意味:
- オレンジ色(Wizard / Perfect): 完全に理想的なモデル。予知能力があった場合の理論上の上限を示します。
- 緑の点線(Random): ランダムに選んだ場合の基準線。モデルを使わない場合の結果に相当します。
- 青い線(Cumulative Gain): 今回のモデルの実際の性能。緑の点線より上に大きく膨らんでいるほど、モデルの精度が高いといえます。
画像の数値「Lift at 40% is 1.3609」の意味:
予測スコアの高い上位40%にのみアプローチした場合、ランダムに40%を選んだ場合と比べて、1.36倍効率よく正解者(再入院患者)を見つけ出せていることを意味します。
- 下のグラフ:Per-bin lift chart(デシル分析)
データを予測スコアの高い順に10等分(各10%のグループ)し、グループごとの「再入院予測の濃度」を示したグラフです。このAIを使うことで、再入院リスクの高い患者をどれだけ効率よく特定できるかを視覚的に確認できます。
- 左端の棒(Bin 1): 「再入院する可能性が最も高い」と予測された上位10%のグループ
- 右端の棒(Bin 10): 「再入院する可能性が最も低い」と予測された下位10%のグループ
- 赤い点線(1.0): 平均ライン(ランダム選択と同等の基準)
- 具体的な読み方:
Bin 1(左端)の患者グループ
- AIの判定: 「最も危険度が高い」とされた上位10%の患者リストです。
- リフト値1.66の意味: 平均的な患者と比べて、1.66倍再入院しやすいグループであることを示しています。
- 現場での活用: このリストに含まれる患者には、退院前に重点的な指導や特別対応を実施する優先対象として活用できます。
Bin 10(右端)の患者グループ
- AIの判定: 「再入院の可能性がほとんどない」と判定された下位10%の患者リストです。
- リフト値0.3(低い値)の意味: このグループの患者は、再入院する可能性が非常に低いことを示しています。
- 現場での活用: 過剰なフォローアップは不要と判断し、通常の退院手続きで対応することで、医療リソースを効率的に配分できます。
- 結論:どうビジネスに使うか?
このチャートは、限られたリソースの優先配分を決める際に活用します。
たとえば、「全患者にフォローアップの連絡を送る余裕がない」という状況であれば、下のグラフを参照して「Bin 1〜Bin 4(上位40%)」を対応対象とすることを検討します。これにより、不要な対応を減らしながら、再入院リスクの高い患者の多くを効率よくカバーできます。
今回のモデルは棒グラフが左から右へきれいな階段状に低下しており、患者の優先順位付け(リスクランキング)のツールとして非常に有効であるといえます。
Density chart
Density chart(密度チャート)は、モデルが各クラスをどの程度正確に識別・分離できているかを示すグラフです。理想的なモデルでは異なるクラス間の確率密度が重なり合うことはありませんが、実際のデータで学習したモデルでそのような状態になることはほとんどありません。今回のXGBoostモデルでは、2つの分布がある程度分かれていることが確認でき、それぞれの中央値には予測確率で12%の差があります。 このグラフを読む際は、「山の形」と「重なり具合」に着目することがポイントです。
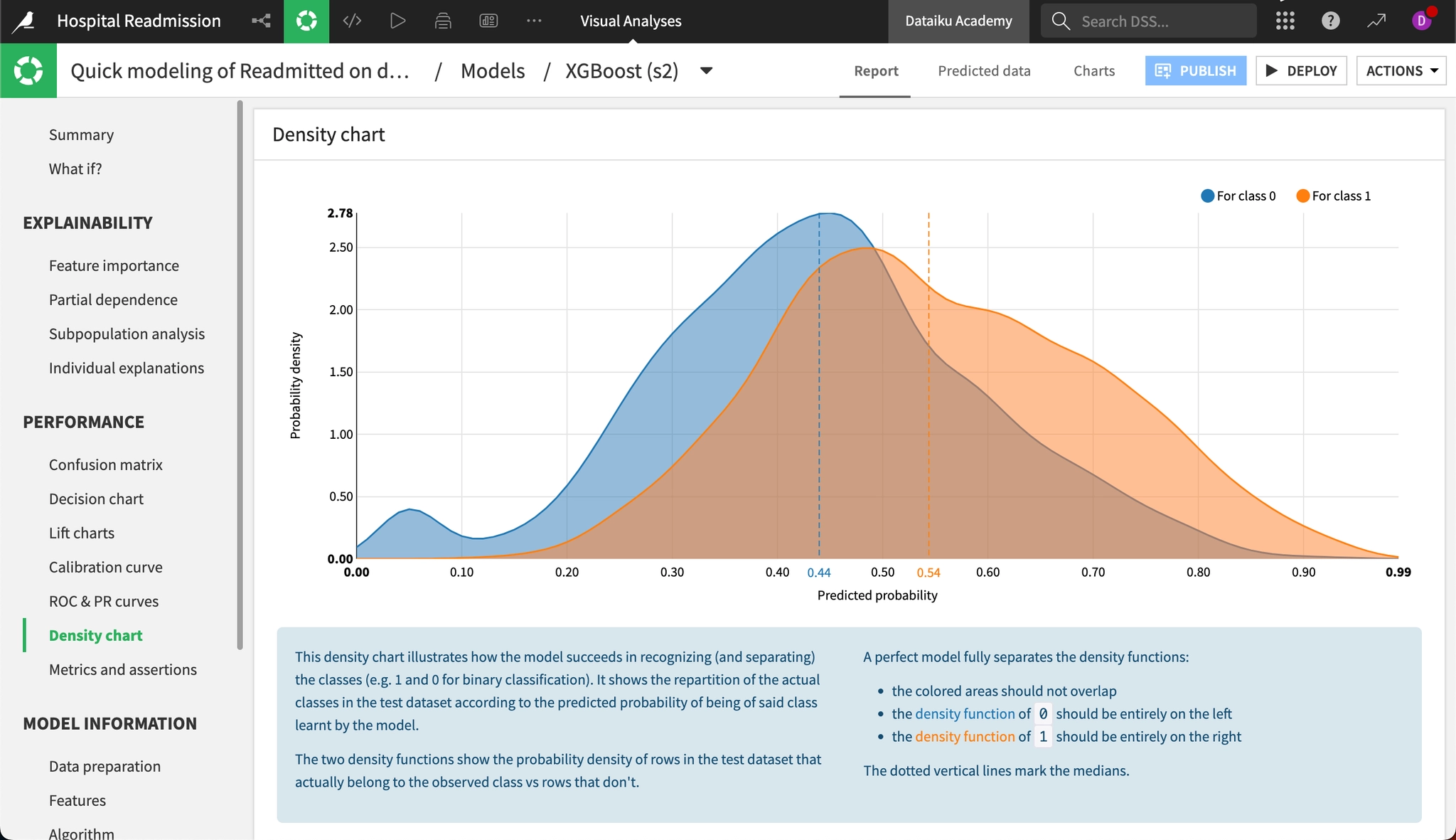
グラフの基本構成
- 横軸 (Predicted probability): モデルが出した予測スコア(0.0〜1.0)。
- 左側 (0.0): 「絶対に再入院しない」という判定。
- 右側 (1.0): 「絶対に再入院する」という判定。
- 縦軸 (Probability density): そのスコアを出した人数の多さ(山の高さ)。
- 2つの色の山:
- 青い山 (Class 0): 実際には再入院しなかった人たち のスコア分布。
- オレンジの山 (Class 1): 実際に再入院した人たち のスコア分布。
理想的な形と現実の比較
このチャートを見る際は、「青とオレンジの山が左右にきれいに分かれているか」を確認します。
- 理想的なモデル(満点):
- 青い山が左端(0付近)に集中している
- オレンジの山が右端(1付近)に集中している
- 中央で重なり合う部分がまったくない状態
- 精度の低いモデル:
- 青とオレンジの山が中央で完全に重なっている(=モデルが両クラスを区別できていない状態)
今回の結果の診断:「判別に苦戦しているが、傾向は捉えている」
今回の結果からは、以下のことが読み取れます。
- 重なり(Overlap)が非常に大きい: 中央部の茶色がかったエリア(青とオレンジが重なっている領域)が非常に広くなっています。これは、予測スコアが0.4〜0.6付近の領域では、実際に再入院した人としなかった人が混在しており、モデルが明確に判別できていないことを意味します。
- 中央値の位置が近い:
- 青の点線(中央値):0.44
- オレンジの点線(中央値):0.54
- 両者の差はわずか0.1ポイントです。モデルは「再入院する人」に対してわずかに高いスコアを付けられているものの、その差は小さいといわざるを得ません。
結論: このモデルにとって、再入院の予測は**「難易度の高い(グレーゾーンが多い)タスク」**であるといえます。両クラスを明確に区別できる特徴量を十分に捉えられておらず、モデルが判断に迷いながら予測している様子がこのグラフから見て取れます。
Features
Features(特徴量)パネルには、特徴量の取り扱いに関する情報と、前処理されたすべての特徴量の一覧が表示されます。今回のXGBoostモデルでは、「Encounter ID」が除外(Rejected)された一方、「救急来院数(Number of emergency visits)」は数値型として処理され、標準化(Standardized)されていることが確認できます。
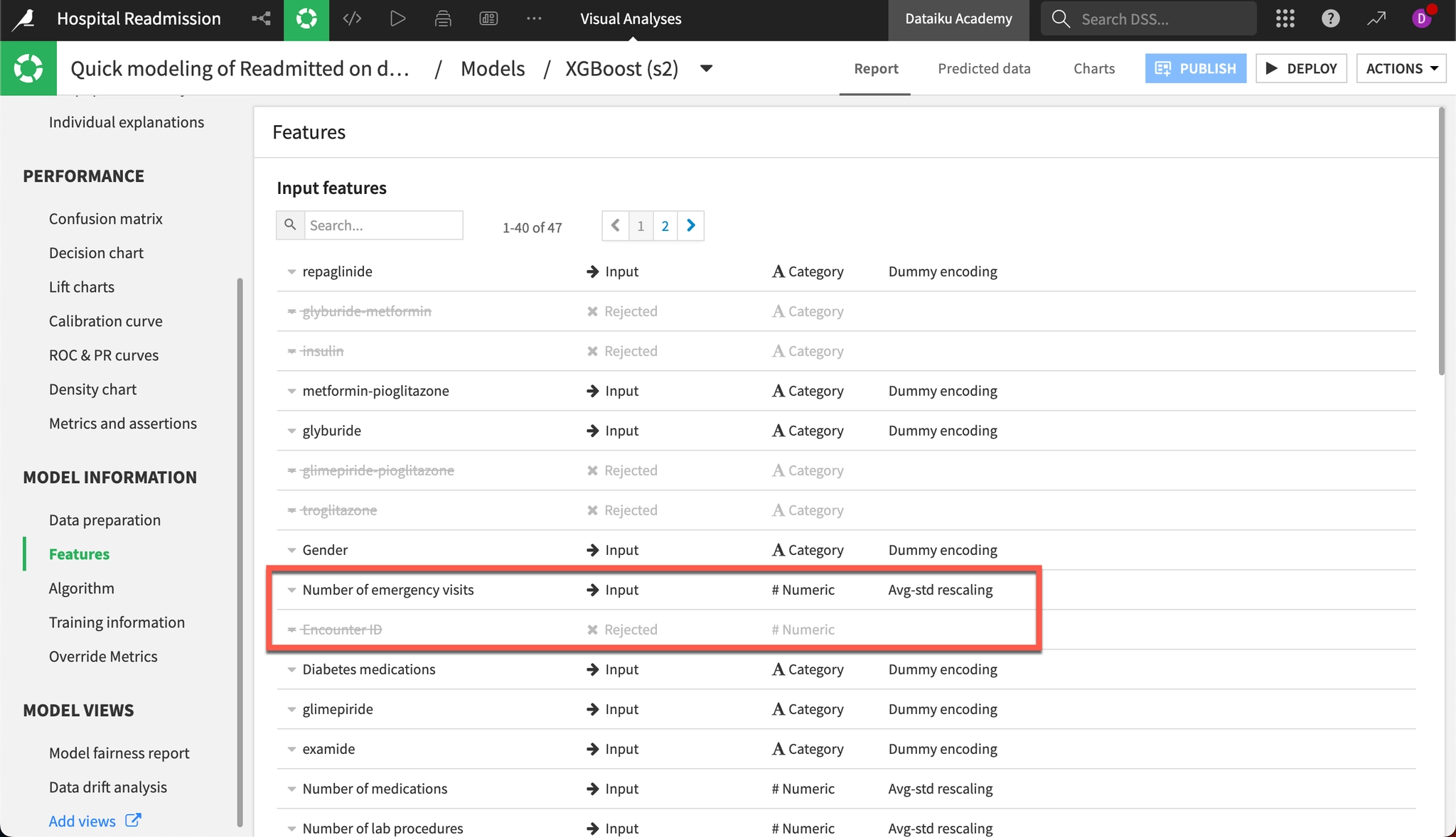
赤枠部分の見方:
- Status(矢印の列): 最も重要な項目です。
Input(→): その変数が予測に有用であると判断され、モデルに採用されたことを示します。Rejected(×): その変数が不要または予測に悪影響を及ぼすと判断され、除外されたことを示します。
- 具体的な例(赤枠の中身):
Number of emergency visits(Input):「救急外来の受診回数」は予測に有効な情報を持つと判断され、採用されています。Encounter ID(Rejected):「診察IDなどの識別番号」は患者ごとに異なる単なる通し番号であり、予測に意味のある情報を持たないため、Dataikuによって自動的に除外されています。
Algorithm
Algorithm(アルゴリズム)パネルには、ハイパーパラメータのグリッドサーチの結果得られた最適なモデルの情報が表示されます。
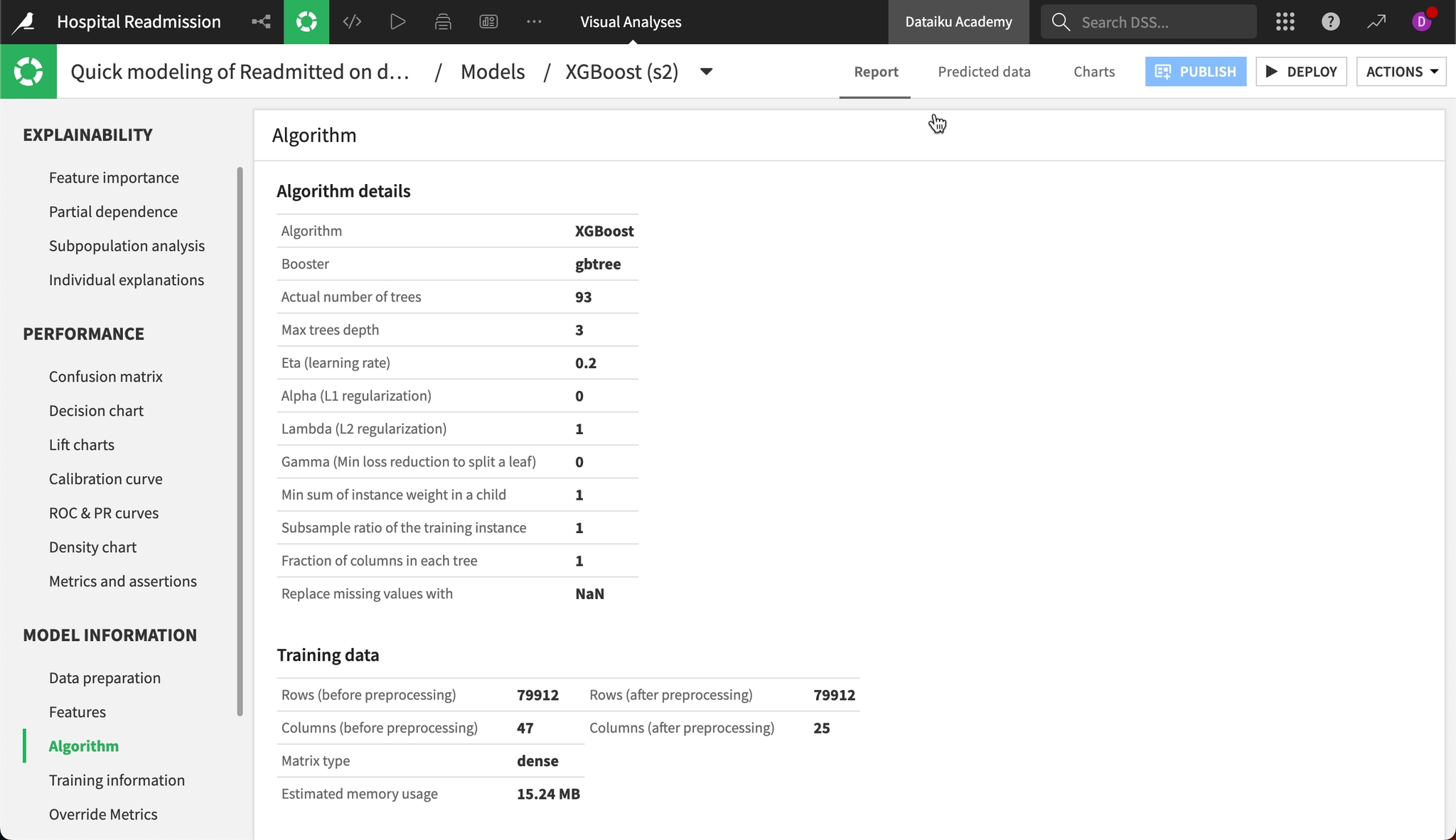
これまでの画面が主に「精度の評価」を目的としていたのに対し、この画面は「どのような設定でモデルが学習されたか」という技術的な事実を確認するためのものです。画面は大きく2つのセクションに分かれています。
Algorithm details(アルゴリズム詳細)
Dataikuがグリッドサーチなどの実験を経て、最終的に採用したパラメータ設定の一覧が表示されます。特に注目すべき項目は以下の通りです。
- Algorithm: XGBoost
- 使用されたアルゴリズムです。
- Actual number of trees: 93
- ここが重要です。 実際に生成された決定木の数です。たとえば設計画面(Design)で「最大100本」と設定していたにもかかわらず結果が93本であれば、「93本の時点で十分な精度に達したため、早期に学習を打ち切りました(Early Stopping)」を意味します。これは過学習を防ぐうえで望ましい挙動です。
- Max trees depth: 3
- 決定木の深さです。値が大きいほど複雑なルールを学習できますが、3程度であればシンプルで汎用性の高いモデルといえます。
- Eta (learning rate): 0.2
- 学習率です。1回の学習ステップでどれだけパラメータを更新するかを制御する設定です。
活用場面:「このモデルの精度をさらに高めたい」と考えた際に、この値を参考に次の実験計画を立てます。たとえば「木の深さが上限の3に達しているため、次は5まで試してみよう」といった判断に役立てることができます。
Training data(学習データの統計)
ここでは、学習に使われたデータの量(行と列)の変化を確認できます。
- Rows (行数): 79912 → 79912
- BeforeとAfterで変化がないため、フィルタリングなどによるデータの除外は発生していないことがわかります。
- Columns (列数): 47 → 25 ★ 要チェック
- ここは特に重要です。元々47個あった変数が、学習時には25個に削減されています。これは、Dataikuが「全員同じ値を持つ変数」や「互いに相関が強すぎる変数(多重共線性)」を自動的に除外する機能(Feature Reduction)によるものです。約半数の変数が自動的に整理され、モデルがスリム化されたことを示しています。
まとめ
以上が、DataikuのPERFORMANCEタブおよびMODEL INFORMATIONタブに含まれる各画面の見方と解釈のポイントです。 Confusion Matrixで予測の傾向をつかみ、Decision chartでしきい値とビジネス損益の関係を理解し、Lift chartで優先順位付けの効果を確認する――それぞれの画面が「モデルの精度を多角的に評価する」という一つの目的のもとにつながっていることが、今回の学習を通じてよく分かりました。 どの画面で何を確認すればよいかが分かると、モデル作成がより楽しくなりますし、精度改善のヒントも見つけやすくなります。「Machine Learning Basics」は、DataikuにおけるAutoMLの基礎を体系的に学ぶうえで非常に役立つコンテンツでした。 今後は、今回読み解いた結果をもとに行う「モデルの再調整」や「特徴量エンジニアリング」など、精度向上に向けたプロセスについても学び、発信していきたいと思います。 最後まで読んでいただき、ありがとうございました。



