Google ADK公式サンプルで学ぶ:マルチエージェントで作るData Scienceシステム(BigQuery×Python可視化)

Google ADK(Agent Development Kit)の公式サンプル「data-science」を題材に、Root Agentが複数の専門エージェント(BigQuery/Analytics/AlloyDB/BQML)を束ねて“データ取得→分析→可視化”までを自然言語で実行する仕組みを解説します。エージェント間のデータ受け渡しにtool_context.stateを使う疎結合パターン、NL2SQLのBASELINEとCHASE-SQLの使い分け、拡張しやすい設計の考え方までを押さえます。
注意
本記事は2026年1月22日時点のadk-samplesに基づいています。最新版ではサンプルデータセット、設定ファイル形式、およびBigQuery接続方法などが更新されている可能性があります。最新情報は公式リポジトリをご確認ください。
はじめに
Google ADK(Agent Development Kit)を使えば、単一のエージェントを簡単に作成できます。
しかし、現実の業務では「SQLでデータを取得して、Pythonで分析して、グラフを作成する」といった複数のスキルを組み合わせた処理が必要になります。一つのエージェントにすべてを任せると、プロンプトが肥大化し、メンテナンスが困難になります。
そこで登場するのがマルチエージェントアーキテクチャです。
本記事では、Google ADKの公式サンプル「data-science」を使って、複数のエージェントが協調して動作する仕組みを解説します。
アーキテクチャ概観
全体構成
data-scienceサンプルは、Root Agentが4つの専門エージェントを束ねる構造になっています。
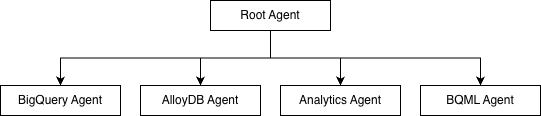
各エージェントの役割
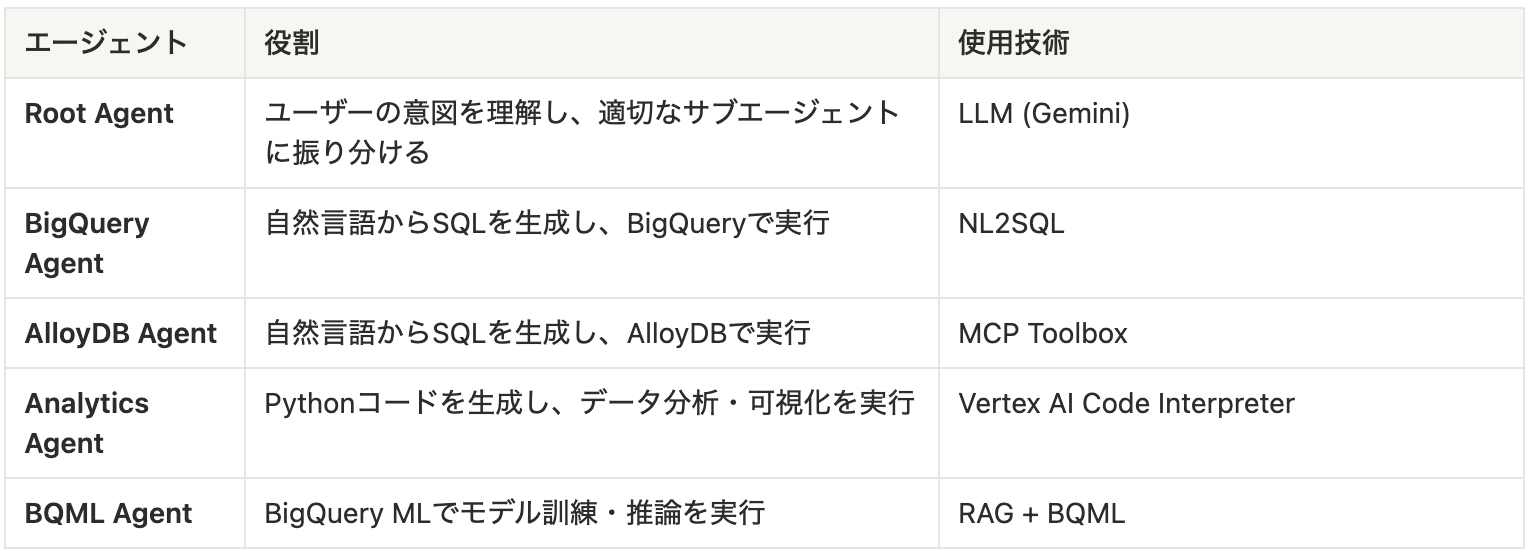
なぜこの設計なのか?
- 専門性の分離: SQLの専門家、Pythonの専門家、MLの専門家がそれぞれ担当
- 保守性の向上: 各エージェントのプロンプトが小さく保てる
- 拡張性: 新しい専門エージェントを追加しやすい
動かしてみる
環境構築
# リポジトリをクローン
git clone <https://github.com/google/adk-samples.git>
cd adk-samples/python/agents/data-science
# 依存関係をインストール
uv sync
# .envファイルを設定
cp .env.example .env
.envファイルの以下の項目を編集します:
# Vertex AIを使用する場合は1に設定
GOOGLE_GENAI_USE_VERTEXAI=1
# GCPプロジェクトの設定
GOOGLE_CLOUD_PROJECT=your-project-id # GCPコンソールで確認
GOOGLE_CLOUD_LOCATION=us-central1 # リージョン
# BigQueryの設定
BQ_COMPUTE_PROJECT_ID=your-project-id # 同じプロジェクトIDでOK
BQ_DATA_PROJECT_ID=your-project-id # 同じプロジェクトIDで
OKBQ_DATASET_ID=your_dataset_name # 作成するデータセット名
GCPプロジェクトIDは、Google Cloud Consoleの左上で確認できます。
# サンプルデータをBigQueryにロード(train/testテーブルを作成)
uv run python3 data_science/utils/create_bq_table.py
# サーバーを起動
uv run adk web
BigQuery Agent を試す
ターミナルに表示されるURLをブラウザで開き、data_science エージェントを選択します。
「trainテーブルの行数を教えて」と入力すると、以下のように動作します:
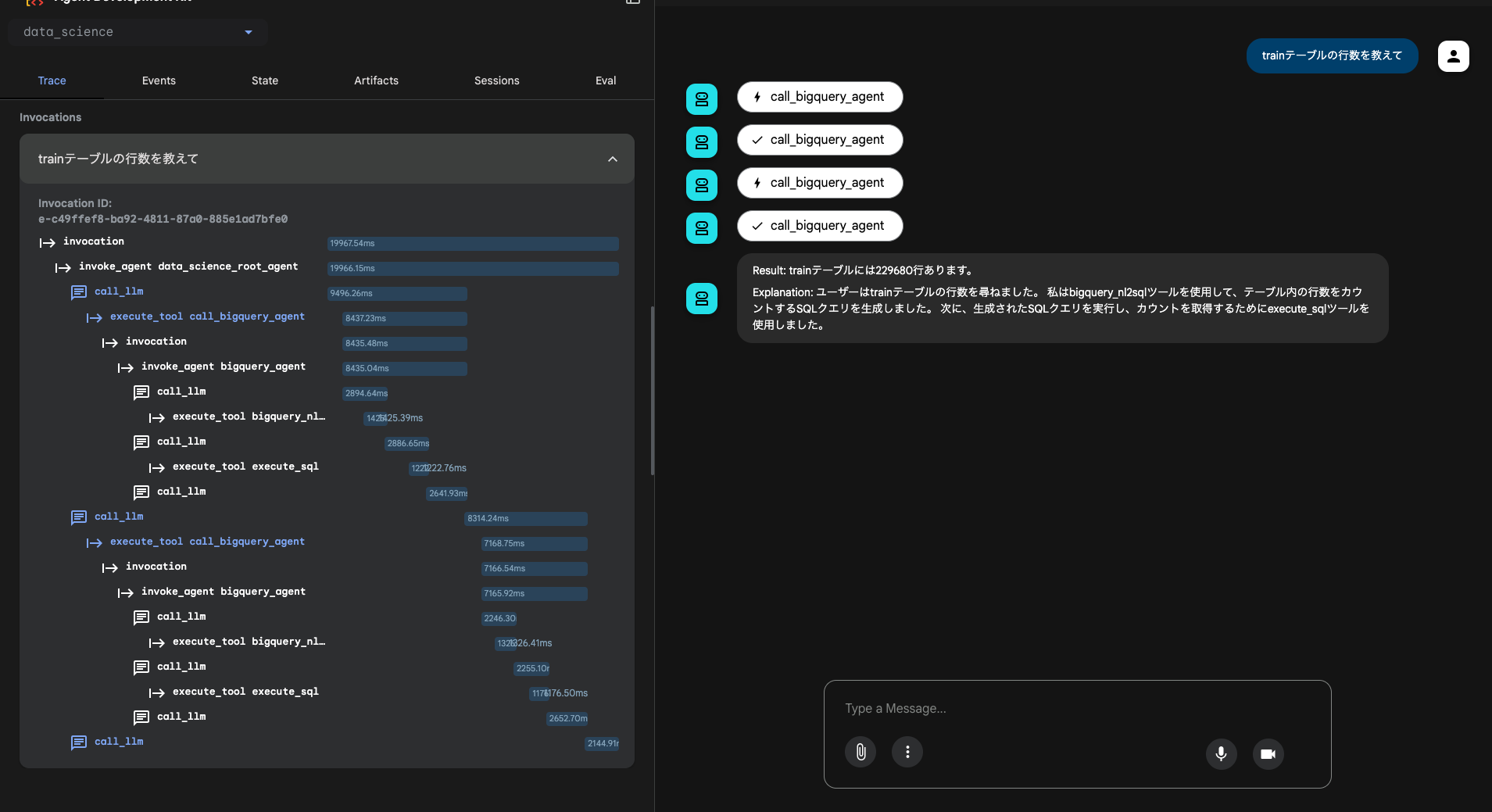
Root Agentが質問を受け取り、call_bigquery_agentを呼び出しています。BigQuery Agentは内部で:
bigquery_nl2sqlツールでSQLを生成execute_sqlツールでクエリを実行- 結果(229,680行)を返答
このように、自然言語からSQLが自動生成され、実行される仕組みです。
Analytics Agent を試す
次に、「trainテーブルのcountry別の売上合計を棒グラフで表示して」と入力してみます。
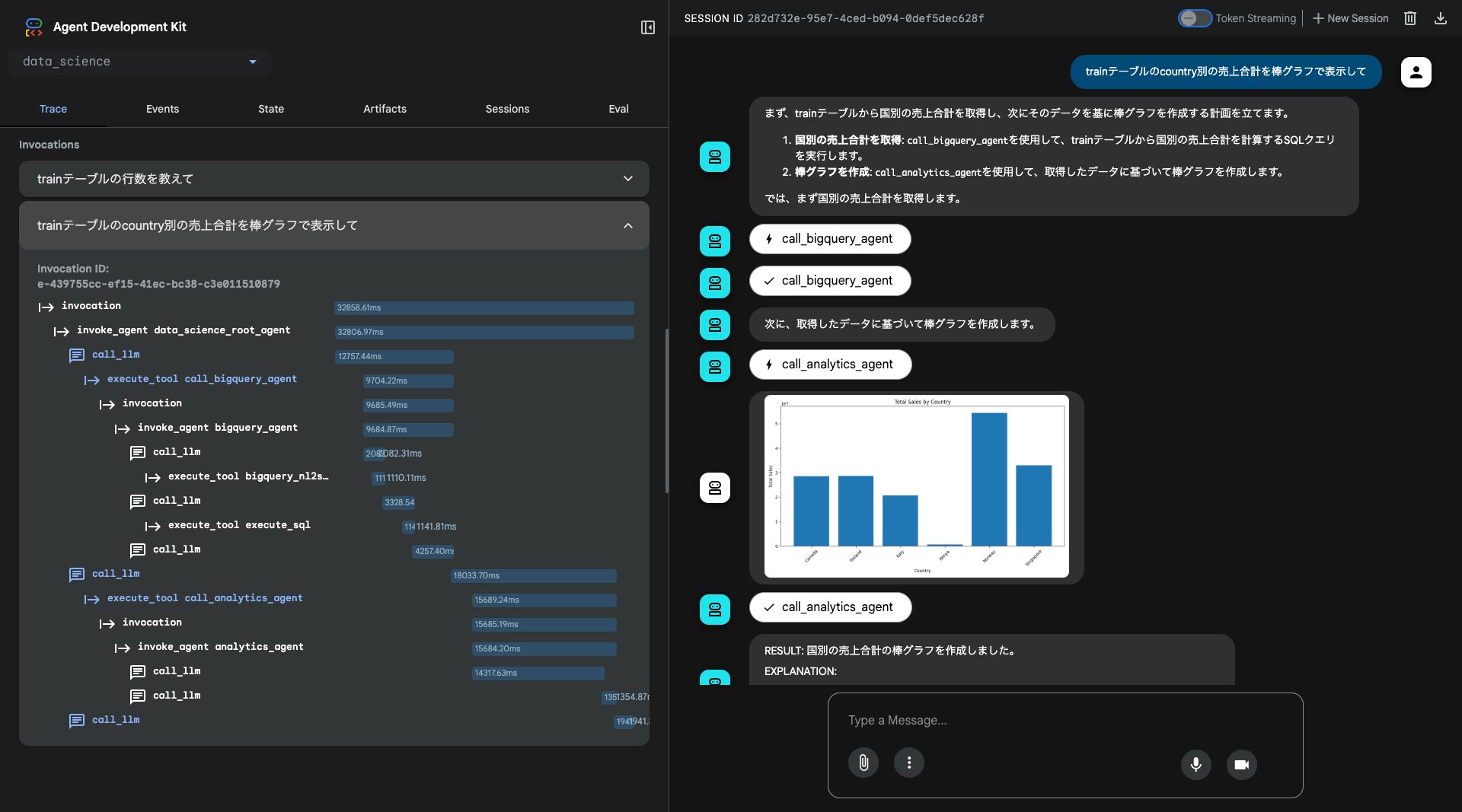
今度は2つのエージェントが連携しています:
- BigQuery Agent: データを取得
- Analytics Agent: Pythonコードを生成し、グラフを描画
Analytics AgentはVertex AI Code Interpreterを使用しており、matplotlibでグラフを生成しています。データ取得から可視化まで、自然言語の指示だけで完結します。
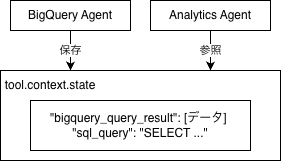
状態共有の仕組み:tool_context.state
マルチエージェントで最も重要なのは「エージェント間でどうデータを共有するか」です。
このサンプルでは、tool_context.stateという共有辞書を使ったシンプルなパターンを採用しています。
データフロー
コード例
BigQuery Agentがクエリ結果を保存:
# BigQuery Agent のツール内
tool_context.state["bigquery_query_result"] = query_results
tool_context.state["sql_query"] = generated_sql
Analytics Agentがデータを参照して分析:
# Analytics Agent のツール内
data = tool_context.state.get("bigquery_query_result")
# → pandas DataFrame として分析・可視化
NL2SQL:2つの手法
BigQuery Agentには、自然言語からSQLを生成する2つの手法が実装されています。
BASELINE(ベースライン)
シンプルな1回のLLM呼び出しでSQLを生成します。
ユーザーの質問 → LLMに1回プロンプト → SQL出力
メリット:
- 高速(1回のAPI呼び出し)
- コストが低い
デメリット:
- 複雑なクエリで精度が落ちやすい
CHASE-SQL(チェイスSQL)
ICLR 2025で発表された最新手法。複数ステップの推論で精度を上げます。
複雑な質問
↓ Divide(分解)
サブ質問1, サブ質問2, サブ質問3
↓ Conquer(各サブ質問のSQL生成)
SQL断片1, SQL断片2, SQL断片3
↓ Combine(統合・最適化)
最終SQL
メリット:
- 複雑なクエリでも高精度
デメリット:
- 処理時間が長い
- コストが高い(複数回のAPI呼び出し)
切り替え方法
# シンプル・高速 BQ_NL2SQL_METHOD="BASELINE" # 高精度・低速 BQ_NL2SQL_METHOD="CHASE" その他のエージェント
今回は試せませんでしたが、data-scienceサンプルには以下のエージェントも含まれています。
AlloyDB Agent
PostgreSQL互換のAlloyDBに対してNL2SQLを実行するエージェントです。MCP Toolbox for Databasesを使用しており、BigQueryとAlloyDBを組み合わせたクロスデータベースクエリも可能です。
BQML Agent
BigQuery MLを使った機械学習モデルの訓練・推論を行うエージェントです。RAG(Retrieval-Augmented Generation)を使ってBQMLのドキュメントを参照しながら、適切なMLコードを生成します。
まとめ
本記事では、Google ADKの公式サンプル「data-science」を通じて、以下を学びました。
- マルチエージェントアーキテクチャ: Root Agentが専門エージェントを束ねる階層構造
- エージェント連携の実例: BigQuery Agent → Analytics Agent のデータ連携
- 状態共有パターン:
tool_context.stateによる疎結合なデータ受け渡し - NL2SQL手法の選択: BASELINEとCHASE-SQLの使い分け
マルチエージェントアーキテクチャを採用することで、各エージェントの責務を明確に分離し、保守性と拡張性の高いシステムを構築できます。


